I’m curious how software can be created and evolve over time. I’m afraid that at some point, we’ll realize there are issues with the software we’re using that can only be remedied by massive changes or a complete rewrite.
Are there any instances of this happening? Where something is designed with a flaw that doesn’t get realized until much later, necessitating scrapping the whole thing and starting from scratch?
Happens all the time on Linux. The current instance would be the shift from X11 to Wayland.
The first thing I noticed was when the audio system switched from OSS to ALSA.
And then ALSA to all those barely functional audio daemons to PulseAudio, and then again to PipeWire. That sure one took a few tries to figure out right.
And the strangest thing about that is that neither PulseAudio nor Pipewire are replacing anything. ALSA and PulseAudio are still there while I handle my audio through Pipewire.
How is PulseAudio still there? I mean, sure the protocol is still there, but it’s handled by
pipewire-pulseon most systems nowadays(KDE specifically requires PipeWire).Also, PulseAudio was never designed to replace ALSA, it’s sitting on top of ALSA to abstract some complexity from the programs, that would arise if they were to use ALSA directly.
Pulse itself is not there but its functionality is (and they even preserved its interface and pactl). PipeWire is a superset of audio features from Pulse and Jack combined with video.
For anyone wondering: Alsa does sound card detection and basic IO at the kernel level, Pulse takes ALSA devices and does audio mixing at the user/system level. Pipe does what Pulse does but more and even includes video devices
And then from ALSA to PulseAudio haha
They’re at different layers of the audio stack though so not really replacing.
there are issues with the software we’re using that can only be remedied by massive changes or a complete rewrite.
I think this was the main reason for the Wayland project. So many issues with Xorg that it made more sense to start over, instead of trying to fix it in Xorg.
And as I’ve understood and read about it, Wayland had been a near 10 years mess that ended up with a product as bad or perhaps worse than xorg.
Not trying to rain on either parade, but x is like the Hubble telescope if we added new upgrades to it every 2 months. Its way past its end of life, doing things it was never designed for.
Wayland seems… To be missing direction?
I do not want to fight and say you misunderstood. Let’s just say you have been very influenced by one perspective.
Wayland has taken a while to fully flesh out. Part of that has been delay by the original designers not wanting to compromise their vision. Most of it is just the time it takes to replace something mature ( X11 is 40 years old ). A lot of what feels like Wayland problems actually stem from applications not migrating yet.
While there are things yet to do, the design of Wayland is proving itself to be better fundamentally. There are already things Wayland can do that X11 likely never will ( like HDR ). Wayland is significantly more secure.
At this point, Wayland is either good enough or even superior for many people. It does not yet work perfectly for NVIDIA users which has more to do with NVIDIA’s choices than Wayland. Thankfully, it seems the biggest issues have been addressed and will come together around May.
The desktop environments and toolkits used in the most popular distros default to Wayland anlready and will be Wayland only soon. Pretty much all the second tier desktop environments have plans to get to Wayland.
We will exit 2024 with almost all distros using Wayland and the majority of users enjoying Wayland without issue.
X11 is going to be around for a long time but, on Linux, almost nobody will run it directly by 2026.
Wayland is hardly the Hubble.
Well, as I said, it’s what I read. If it’s better than that, great. Thanks for correcting me
Also, X is Hubble, not Wayland :)
I’ve been using Wayland on plasma 5 for a year or so now, and it looks like the recent Nvidia driver has merged, so it should be getting even better any minute now.
I’ve used it for streaming on Linux with pipewire, overall no complaints.
Wayland is the default for GNOME and KDE now, meaning before long it will become the default for the majority of all Linux users. And in addition, Xfce, Cinnamon and LXQt are also going to support it.
according to kagiGPT…
~~i have determined that wayland is the successor and technically minimal:
*Yes, it is possible to run simple GUI programs without a full desktop environment or window manager. According to the information in the memory:You can run GUI programs with just an X server and the necessary libraries (such as QT or GTK), without needing a window manager or desktop environment installed. [1][2]
The X server handles the basic graphical functionality, like placing windows and handling events, while the window manager is responsible for managing the appearance and behavior of windows. [3][4]
Some users prefer this approach to avoid running a full desktop environment when they only need to launch a few GUI applications. [5][6]
However, the practical experience may not be as smooth as having a full desktop environment, as you may need to manually configure the environment for each GUI program. [7][8]*~~
however… firefox will not run without the full wayland compositor.
correction:
-
Wayland is not a display server like X11, but rather a protocol that describes how applications communicate with a compositor directly. [1]
-
Display servers using the Wayland protocol are called compositors, as they combine the roles of the X window manager, compositing manager, and display server. [2]
-
A Wayland compositor combines the roles of the X window manager, compositing manager, and display server. Most major desktops support Wayland compositors. [3]
-
There is some Rust code that needs to be rewritten in C.
Bold
Italics
I feel tracked… Better strike this all through
Strange. I’m not exactly keeping track. But isn’t the current going in just the opposite direction? Seems like tons of utilities are being rewritten in Rust to avoid memory safety bugs
You got it right, the person you replied to made a joke.
The more the code is used, the faster it ought to be. A function for an OS kernel shouldn’t be written in Python, but a calculator doesn’t need to be written in assembly, that kind of thing.
I can’t really speak for Rust myself but to explain the comment, the performance gains of a language closer to assembly can be worth the headache of dealing with unsafe and harder to debug languages.
Linux, for instance, uses some assembly for the parts of it that need to be blazing fast. Confirming assembly code as bug-free, no leaks, all that, is just worth the performance sometimes.
But yeah I dunno in what cases rust is faster than C/C++.
C/C++ isn’t really faster than Rust. That’s the attraction of Rust; safety AND speed.
Of course it also depends on the job.

https://benchmarksgame-team.pages.debian.net/benchmarksgame/box-plot-summary-charts.html
C/C++ isn’t
You’re talking about two languages, one is C, the other is C++. C++ is not a superset of C.
Yes thank you. But my statement remains true nevertheless.
But yeah I dunno in what cases rust is faster than C/C++.
First of all C and C++ are very different, C is faster than C++. Rust is not intrinsically faster than C in the same way that C is faster than C++, however there’s a huge difference, safety.
Imagine the following C function:
void do_something(Person* person);Are you sure that you can pass NULL? Or that it won’t delete your object? Or delete later? Or anything, you need to know what the function does to be sure and/or perform lots of tests, e.g. the proper use of that function might be something like:
if( person ) { person_uses++; do_something(person); } ... if( --person_uses == 0 ) free( person )That’s a lot more calls than just calling the function, but it’s also a lot more secure.
In C++ this is somewhat solved by using smart pointers, e.g.
void do_something(std::unique_ptr<Person> person); void something_else(std::shared_ptr<Person> person);That’s a lot more secure and readable, but also a lot slower. Rust achieves the C++ level of security and readability using only the equivalent of a single C call by performing pre-compile analysis and making the assembly both fast and secure.
Can the same thing be done on C? Absolutely, you could use macros instead of ifs and counters and have a very fast and safe code but not easy to read at all. The thing is Rust makes it easy to write fast and safe code, C is faster but safe C is slower, and since you always want safe code Rust ends up being faster for most applications.
Rust is faster than C. Iterators and mutable noalias can be optimized better. There’s still FORTRAN code in use because it’s noalias and therefore faster
Agree, call me unreasonable or whatever but I just don’t like Rust nor the community behind it. Stop trying to reinvent the wheel! Rust makes everything complicated.
On the other hand… Zig 😘
deleted by creator
Zig!!
Zig!!
Starting anything from scratch is a huge risk these days. At best you’ll have something like the python 2 -> 3
rewriteoverhaul (leaving scraps of legacy code all over the place), at worst you’ll have something like gnome/kde (where the community schisms rather than adopting a new standard). I would say that most of the time, there are only two ways to get a new standard to reach mass adoption.-
Retrofit everything. Extend old APIs where possible. Build your new layer on top of https, or javascript, or ascii, or something else that already has widespread adoption. Make a clear upgrade path for old users, but maintain compatibility for as long as possible.
-
Buy 99% of the market and declare yourself king (cough cough chromium).
Python 3 wasn’t a rewrite, it just broke compatibility with Python 2.
In a good way. Using a non-verified bytes type for strings was such a giant source of bugs. Text is complicated and pretending it isn’t won’t get you far.
-
The entire thing. It needs to be completely rewritten in rust, complete with unit tests and Miri in CI, and converted to a high performance microkernel. Everything evolves into a crab /s
I laughed waay too hard at this.
A PM said something similar earlier this week during a performance meeting: “I heard rust was fast. Maybe we should rewrite the software in that?”
They must have been a former Duke Nukem Forever project manager
Had me in the first half ngl
Why not Ironclad( written in Ada) ? https://ironclad.nongnu.org/
Maybe not exaclly Linux, sorry for that, but it was first thing that get to my mind.
Web browsers really should be rewritten, be more modular and easier to modify. Web was supposed to be bulletproof and work even if some features are not present, but all websites are now based on assumptions all browsers have 99% of Chromium features implemented and won’t work in any browser written from scratch now.The same guys who create Chrome have stuffed the web standards with needlessly bloated fluff that makes it nearly impossible for anyone else to implement it. If alternative browsers have to be a thing again, we need a new standard, or at least the current standard with significantly large portions removed.
we need to just rebuild the web, built on a decentralized LoRa or such mesh network.
WWW ≠ Internet.
Internet has some things to be fixed too (https://secushare.org/broken-internet), but is not as doomed as the web.
That sounds like amp, no thanks.
Most of the standards themselves aren’t the problem, we just shouldn’t have to rely so badly on them that a site immediately is dead if a small item is not available
Agreed. I mean, metadata should be protocol stuff, not document stuff. And rendering (font size etc) should be user side, not developer side. Browser should be modular, not a monolith. Creating a webpage should be easy again.
If you want a browser truly written “from scratch”, you need to check-out Ladybird:
Linux does this all the time.
ALSA -> Pulse -> Pipewire
Xorg -> Wayland
GNOME 2 -> GNOME 3
Every window manager, compositor, and DE
GIMP 2 -> GIMP 3
SysV init -> SystemD
OpenSSL -> BoringSSL
Twenty different kinds of package manager
Many shifts in popular software
BoringSSL is not a drop-in replacement for openssl though:
BoringSSL is a fork of OpenSSL that is designed to meet Google’s needs.
Although BoringSSL is an open source project, it is not intended for general use, as OpenSSL is. We don’t recommend that third parties depend upon it. Doing so is likely to be frustrating because there are no guarantees of API or ABI stability.
Aren’t different kinds of package managers required due to the different stability requirements of a distro?
We haven’t rewritten the firewall code lately, right? checks Oh, it looks like we have. Now it’s nftables.
I learned ipfirewall, then ipchains, then iptables came along, and I was like, oh hell no, not again. At that point I found software to set up the firewall for me.
Damn, you’re old. iptables came out in 1998. That’s what I learned in (and I still don’t fully understand it).
UFW → nftables/iptables. Never worry about chains again
I was just thinking that iptables lasted a good 20 years. Over twice that of ipchains. Was it good enough or did it just have too much inertia?
Nf is probably a welcome improvement in any case.
GUI toolkits like Qt and Gtk. I can’t tell you how to do it better, but something is definitely wrong with the standard class hierarchy framework model these things adhere to. Someday someone will figure out a better way to write GUIs (or maybe that already exists and I’m unaware) and that new approach will take over eventually, and all the GUI toolkits will have to be scrapped or rewritten completely.
Idk man, I’ve used a lot of UI toolkits, and I don’t really see anything wrong with GTK (though they do basically rewrite it from scratch every few years it seems…)
The only thing that comes to mind is the React-ish world of UI systems, where model-view-controller patterns are more obvious to use. I.e. a concept of state where the UI automatically re-renders based on the data backing it
But generally, GTK is a joy, and imo the world of HTML has long been trying to catch up to it. It’s only kinda recently that we got flexbox, and that was always how GTK layouts were. The tooling, design guidelines, and visual editors have been great for a long time
I’ve really fallen in love with the Iced framework lately. It just clicks.
A modified version of it is what System76 is using for the new COSMIC DE
Desktop apps nowadays are mostly written in HTML with Electron anyway.
Which - in my considered opinion - makes them so much worse.
Is it because writing native UI on all current systems I’m aware of is still worse than in the times of NeXTStep with Interface Builder, Objective C, and their class libraries?
And/or is it because it allows (perceived) lower-cost “web developers” to be tasked with “native” client UI?
Probably mainly a matter of saving costs, you get a web interface and a standalone app from one codebase.
and a mobile app sometimes
Are you aware of macOS? Because it is still built with the same UI tools that you mention.
Aware, yes. Interested, no - closed source philosophy, and the way Apple implements it specifically, turn me off hard.
and all the GUI toolkits will have to be scrapped or rewritten completely
Dillo is the only tool i know still using FLTK.
NUKE
https://www.foundry.com/products/nuke-family/nuke
Also, while a bit of a surprise, FLTK is migrating to Wayland.
Newer toolkits all seem to be going immediate mode. Which I kind of hate as an idea personally.
er, do you have an example. This is not a trend I was aware of
It’s actually a classic programmer move to start over again. I’ve read the book “Clean Code” and it talks about a little bit.
Appereantly it would not be the first time that the new start turns into the same mess as the old codebase it’s supposed to replace. While starting over can be tempting, refactoring is in my opinion better.
If you refactor a lot, you start thinking the same way about the new code you write. So any new code you write will probably be better and you’ll be cleaning up the old code too. If you know you have to clean up the mess anyways, better do it right the first time …
However it is not hard to imagine that some programming languages simply get too old and the application has to be rewritten in a new language to ensure continuity. So I think that happens sometimes.
Yeah, this was something I recognized about myself in the first few years out of school. My brain always wanted to say “all of this is a mess, let’s just delete it all and start from scratch” as though that was some kind of bold/smart move.
But I now understand that it’s the mark of a talented engineer to see where we are as point A, where we want to be as point B, and be able to navigate from A to B before some deadline (and maybe you have points/deadlines C, D, E, etc.). The person who has that vision is who you want in charge.
Chesterton’s Fence is the relevant analogy: “you should never destroy a fence until you understand why it’s there in the first place.”
I’d counter that with monolithic, legacy apps without any testing trying to refactor can be a real pain.
I much prefer starting from scratch, while trying to avoid past mistakes and still maintaining the old app until new up is ready. Then management starts managing and new app becomes old app. Rinse and repeat.
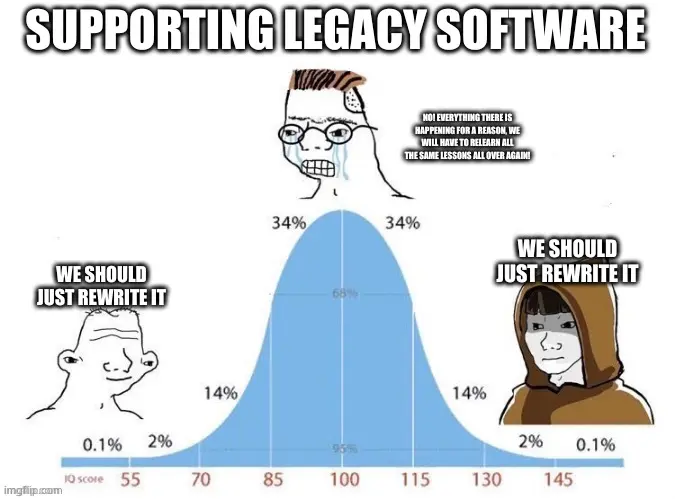
The difference between the idiot and the expert, is the expert knows why the fences are there, and can do the rewrite without having to relearn lessons. But if you’re supporting a package you didn’t originally write, a rewrite is much harder.
Which is something I always try to explain to juniors: writing code is cool, but for your sake learn how to READ code.
Not just understanding what it does, but what was it all meant to do. Even reading your own code is a skill that needs some focus.
Side note: I hate it to my core when people copy code mindlessly. Sometimes it’s not even a bug, or a performance issue, but something utterly stupid and much harder to read. But because they didn’t understand it, and didn’t even try, they just copy-pasted it and went on. Ugh.
Side note: I hate it to my core when people copy code mindlessly
Get ready for the world of AI code assist 😬
Hah yeah, this was in the back of my mind. I forgot the context of it, though, thanks.
“you should never destroy a fence until you understand why it’s there in the first place.”
I like that; really makes me think about my time in building-games.
deleted by creator
Alsa > Pulseaudio > Pipewire
About 20 xdg-open alternatives (which is, btw, just a wrapper around gnome-open, exo-open, etc.)
My session scripts after a deep dive. Seriously, startxfce4 has workarounds from the 80ies and software rot affected formatting already.
Turnstile instead elogind (which is bound to systemd releases)
mingetty, because who uses a modem nowadays?
Pulseaudio doesn’t replace ALSA. Pulseaudio replaces esd and aRts
those last two are just made up words
All words are made up
Except naturally occurring, discovered, onomatopoeic words such as bang, boom, cuckoo, tweet, drip, splish, splash, slosh.
Linux could use a rewrite of all things related to audio from kernel to x / Wayland based audio apps.
Pipewire is great .
Right, sorry.
ALSA is based
About 20 xdg-open alternatives (which is, btw, just a wrapper around gnome-open, exo-open, etc.)
I use handlr-regex, is it bad? It was the only thing I found that I could use to open certain links on certain web applications (like android does), using exo-open all links just opened on the web browser instead.
If you like it, then it’s not bad.
lol that someone already said Wayland.
Your welcome. :)
His welcome?
That’ll teach me to type when I’m mad. “You’re”. There a go.
Actually, it won’t teach me. Wayland’s mere existence will bother me till the day I die, I’m sure. Especially once it’s working well enough for me to have to adopt it. The resentment will grow.
Be careful what you wish for. I’ve been part of some rewrites that turned out worse than the original in every way. Not even code quality was improved.
In corporations, we call that job security.
Just rewriting the same thing in different ways for little gain except to say we did it
Funnily enough the current one is actually the one where we’ve made the biggest delta and it’s been worthwhile in every way. When I joined the oldest part of the platform was 90s .net and MSSQL. This summer we’re turning the last bits off.
Some form of stable, modernized bluetooth stack would be nice. Every other bluetooth update breaks at least one of my devices.
I realize that’s not exactly what you asked for but Pipewire had been incredibly stable for me. Difference between the absolute nightmare of using BT devices with alsa and super smooth experience in pipewire is night and day.
I would say the whole set of C based assumptions underlying most modern software, specifically errors being just an integer constant that is translated into a text so it has no details about the operation tried (who tried to do what to which object and why did that fail).
You have stderr to throw errors into. And the constants are just error codes, like HTTP error codes. Without it how computer would know if the program executed correctly.
stderr is useless if the syscall already returns a single integer only because of stupid C conventions.
You throw an exception like a gentleman. But C doesn’t support them. So you need to abuse the return type to also indicate “success” as well as a potential value the caller wanted.
So you need to abuse the return type to also indicate “success” as well as a potential value the caller wanted.
You don’t need to.
Returnung structs, returning by pointer, signals, error flags, setjmp/longjmp, using cxa for exceptions(lol, now THIS is real abuse).
Exceptionss are bad coding, and what’s abusive of using the full range of an integer? 0 success, everything else, error - check the API for details or call
strerror.errno is bad programming.
Returning error codes in-band is the reason for a significant percentage of C bugs and security holes when the return value is used without checking. Something like Rust’s Result type that forces you to distinguish the two cases is much better design here. And no, you are not working with a whole language ecosystem of “sufficiently disciplined programmers” so that nobody ever forgets to check a return value.
Not to mention that errno is just a very broken design in the times of modern thread and event systems, signals, interrupts and all kinds of other ways to produce race conditions and overwrite the errno value before it is checked.
errno is not shared between threads. Also:
signal handlers that call functions that may set errno or modify the floating-point environment must save their original values, and restore them before returning.
There does not add more race conditions because signal handlers execute in one of regular threads. In single-threaded program signals are functions that can be called by OS at any point of execution, but they do not execute at same time with threads.
You mean 0 indicating success and any other value indicating some arbitrary meaning? I don’t see any problem with that.
Passing around extra error handling info for the worst case isn’t free, and the worst case doesn’t happen 99.999% of the time. No reason to spend extra cycles and memory hurting performance just to make debugging easier. That’s what debug/instrumented builds are for.
Passing around extra error handling info for the worst case isn’t free, and the worst case doesn’t happen 99.999% of the time.
The case “I want to know why this error happened” is basically 100% of the time when an error actually happens.
And the case of “Permission denied” or similar useless nonsense without any details costing me hours of my life in debugging time that wouldn’t be necessary if it just told me permission for who to do what to which object happens quite regularly.
“0.001% of the time, I wanna know every time 👉😎👉”
Yeah, I get that. But are we talking about during development (which is why we’re choosing between C and something else)? In that case, you should be running instrumented builds, or with debug functionality enabled. I agree that most programs just fail and don’t tell you how to go about enabling debug info or anything, and that could be improved.
For the “Permission Denied” example, I also assume we’re making system calls and having them fail? In that case it seems straight forward: the user you’re running as can’t access the resource you were actively trying to access. But if we’re talking about some random log file just saying “Error: permission denied” and leaving you nothing to go on, that’s on the program dumping the error to produce more useful information.
In general, you often don’t want to leak more info than just Worked or Didn’t Work for security reasons. Or a mix of security/performance reasons (possible DOS attacks).
During development is just about the only time when that doesn’t matter because you have direct access to the source code to figure out which function failed exactly. As a sysadmin I don’t have the luxury of reproducing every issue with a debug build with some debugger running and/or print statements added to figure out where exactly that value originally came from. I really need to know why it failed the first time around.
Yeah, so it sounds like your complaint is actually with application not propagating relevant error handling information to where it’s most convenient for you to read it. Linux is not at fault in your example, because as you said, it returns all the information needed to fix the issue to the one who developed the code, and then they just dropped the ball.
Maybe there’s a flag you can set to dump those kinds of errors to a log? But even then, some apps use the fail case as part of normal operation (try to open a file, if we can’t, do this other thing). You wouldn’t actually want to know about every single failure, just the ones that the application considers fatal.
As long as you’re running on a turing complete machine, it’s on the app itself to sufficiently document what qualifies as an error and why it happened.
The whole point of my complaint is that shitty C conventions produce shitty error messages. If I could rely on the programmer to work around those stupid conventions every time by actually checking the error and then enriching it with all relevant information I would have no complaints.
As sysadmin you should know about strace
I know about strace, strace still requires me to reproduce the issue and then to look at backtraces if nobody bothered to include any detail in the error.
Somehow (lack of) backtrace and details in error is “C based assumption”
Ugh, I do not miss C…
Errors and return values are, and should be, different things. Almost every other language figured this out and handles it better than C.
It’s more of an ABI thing though, C just doesn’t have error handling.
And if you do exception handling wrong in most other languages, you hamstring your performance.
The unofficial C motto “Make it fast, who gives a shit about correctness”
Errors and return values are, and should be, different things.
That’s why errno and return value are different things.
Assembly doesn’t have concept of objects.
It does very much have the concept of objects as in subject, verb, object of operations implemented in assembly.
As in who (user foo) tried to do what (open/read/write/delete/…) to which object (e.g. which socket, which file, which Linux namespace, which memory mapping,…).
implemented in assembly.
Indeed. Assembly is(can be) used to implement them.
As in who (user foo) tried to do what (open/read/write/delete/…) to which object (e.g. which socket, which file, which Linux namespace, which memory mapping,…).
Kernel implements it in software(except memory mappings, it is implemented in MMU). There are no sockets, files and namespaces in ISA.
You were the one who brought up assembly.
And stop acting like you don’t know what I am talking about. Syscalls implement operations that are called by someone who has certain permissions and operate on various kinds of objects. Nobody who wants to debug why that call returned “Permission denied” or “File does not exist” without any detail cares that there is hardware several layers of abstraction deeper down that doesn’t know anything about those concepts. Nothing in the hardware forces people to make APIs with bad error reporting.
And why “Permission denied” is bad reporting?
Because if a program dies and just prints strerror(errno) it just gives me “Permission denied” without any detail on which operation had permissions denied to do what. So basically I have not enough information to fix the issue or in many cases even to reproduce it.
It may just not print anything at all. This is logging issue, not “C based assumption”. I wouldn’t be surprised if you will call “403 Forbidden” a “C based assumtion” too.
But since we are talking about local program, competent sysadmin can
straceprogram. It will print arguments and error codes.