

Mid 2022, a friend of mine helped me set up a selfhosted Vaultwarden instance. Since then, my “infrastructure” has not stopped growing, and I’ve been learning each and every day about how services work, how they communicate and how I can move data from one place to another. It’s truly incredible, and my favorite hobby by a long shot.
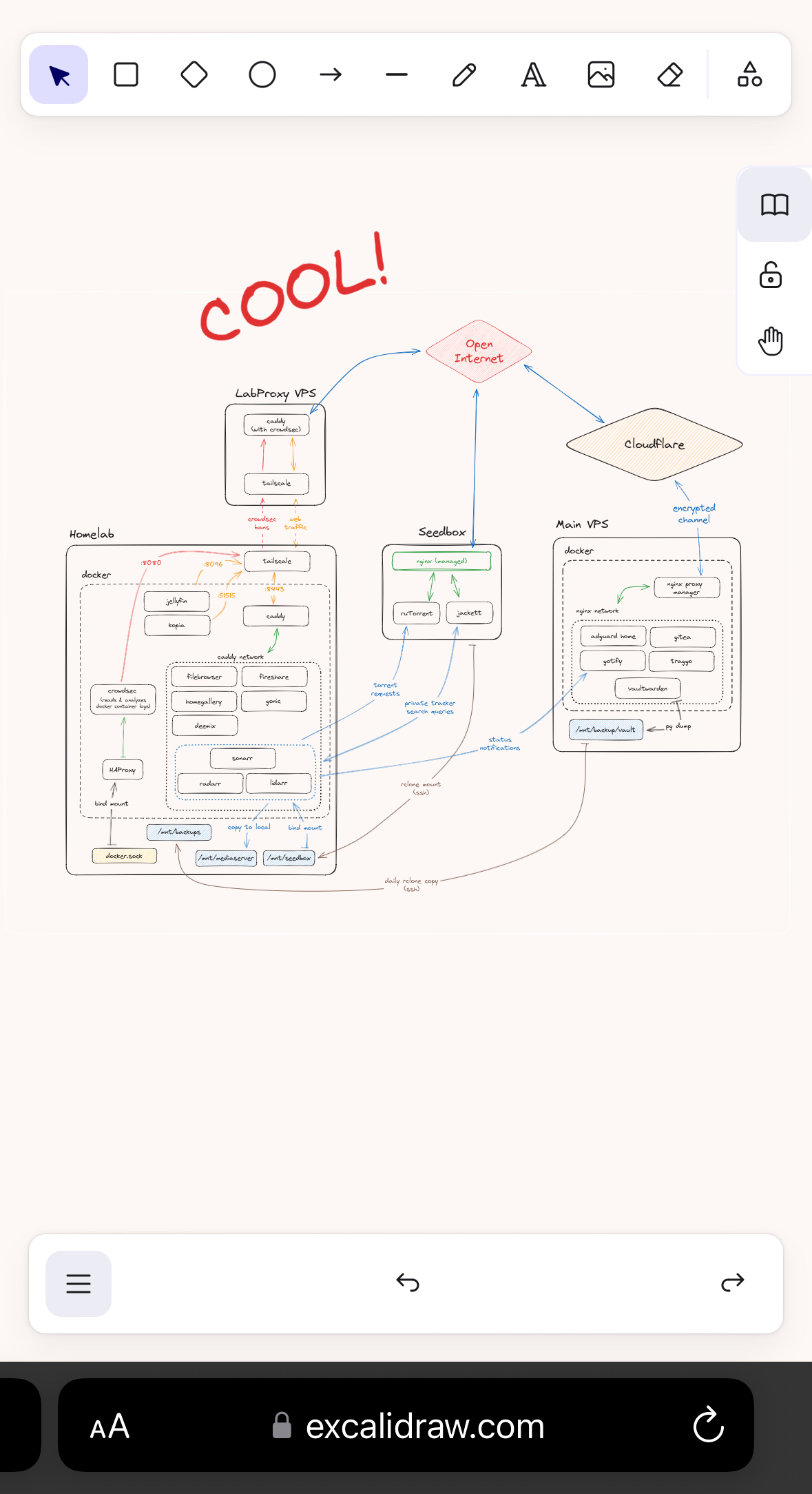
Here’s a map of what I’ve built so far. Right now, I’m mostly done, but surely time will bring more ideas. I’ve also left out a bunch of “technically revelant” connections like DNS resolution through the AdGuard instance, firewalls and CrowdSec on the main VPS.
Looking at the setups that others have posted, I don’t think this is super incredible - but if you have input or questions about the setup, I’ll do my best to explain it all. None of my peers really understand what it takes to construct something like this, so I am in need of people who understand my excitement and proudness :)
Edit: the image was compressed a bit too much, so here’s the full res image for the curious: https://files.catbox.moe/iyq5vx.png And a dark version for the night owls: https://files.catbox.moe/hy713z.png
me after 15 years of intermittent learning self hosting:
i have the one random office PC that runs minecraft
…yeah that’s it
With the enshittification of streaming platforms, a Kodi or Jellyfin server would be a great starting point. In my case, I have both, and the Kodi machine gets the files from the Jellyfin machine through NFS.
Or Home Assistant to help keep IOT devices that tend to be more IoS. Or a Nextcloud server to try to degoogle at least a little bit.
Maybe a personal Friendica instance for your LAN so your family can get their Facebook addiction without giving their data to Meta?
Additionally, using jottacloud with 2 VPS’s (one of them being built on epyc like from OVH cloud) can get you a really good download server and streaming server for about £30 a month, which is the same as having netflix and Disney plus, except now you can have anything you want.
I have a contabo 4core 8gb ram VPS that handles downloading content.
A OVH 4core 8gb VPS that handles emby (I keep trying to go back to jellyfin but it’s just slightly slower than emby at transcoding and I need to squeeze as much performance out of my VPS as possible so… Maybe one day jelly)
And I have a really good streaming experience with subtitles that don’t put big black boxes on the screen making 1/8th of the screen non viewable.
IoS? Internet of stuff?
IoS - internet of shit
Nice
Only host what you need.
This seems like work but from/for home.
You should see some of the literal data centers folks have in their houses. It’s nuts.
I’d recommend using Borgbackup over SSH, instead of just using rclone for backups. As far as I know, rclone is like rsync in that you only have one copy of the data. If it gets corrupted at the source, and that gets synced across, your backup will be corrupted too. Borgbackup and Borgmatic are a great way to do backups, and since it’s deduplicated you can usually store months of daily backups without issue. I do daily backups and retain 7 daily backups, 4 weekly backups, and ‘infinite’ monthly backups (until my backup server runs out of space, then I’ll start pruning old monthly backups).
Borgbackup also has an append-only mode, which prevents deleting backups. This protects the backup in case the client system is hacked. Right now, someone that has unauthorized access to your main VPS could in theory delete both the system and the backup (by connecting via rclone and deleting it). Borg’s append-only mode can be enabled per SSH key, so for example you could have one SSH key on the main VPS that is in append-only mode, and a separate key on your home PC that has full access to delete and prune backups. It’s a really nice system overall.
You’re right, that’s one of the remaining pain points of the setup. The rclone connections are all established from the homelab, so potential attackers wouldn’t have any traces of the other servers. But I’m not 100% sure if I’ve protected the local backup copy from a full deletion.
The homelab is currently using Kopia to push some of the most important data to OneDrive. From what I’ve read it works very similarly to Borg (deduplicate, chunk based, compression and encryption) so it would probably also be able to do this task? Or maybe I’ll just move all backups to Borg.
Do you happen to have a helpful opinion on Kopia vs Borg?
I haven’t tried Kopia, so unfortunately I can’t compare the two. A lot of the other backup solutions don’t have an equivalent to Borg’s append-only mode though.
I’m a borg guy. I’d never heard of kopia. This is from their docs though:
Each snapshot is always incremental. This means that all data is uploaded once to the repository based on file content, and a file is only re-uploaded to the repository if the file is modified. Kopia uses file splitting based on rolling hash, which allows efficient handling of changes to very large files: any file that gets modified is efficiently snapshotted by only uploading the changed parts and not the entire file.
So looks like they do append only.
What I mean by “append-only” is that the client can’t delete the backups. I don’t think Kopia supports that.
Oooh.
Very nice setup imho. Quite a bit more complicated than mine - mine is basically just the left box without being behind a VPS or anything. I don’t expose anything through Caddy except Jellyfin. I’m also running fail2ban in front of my services, so that if it gets hit with too many 404s because someone is poking around, they get IP banned for 30d
I’m still on the fence if I want to expose Jellyfin publicly or not. On the one hand, I never really want to stream movies or shows from abroad, so there’s no real need. And in desperate times I can always connect to Tailscale and watch that way. But on the other, it’s really cool to simply have a web accessible Netflix. Idk.
Honestly, I installed Ombi, so friends can request movies - and gave them all jellyfin logins as well. I’m not running any kind of pay-for service, I’m just giving them access to my library. Additionally, my kids will sometimes spend the night at friends, etc - and their friend won’t have an anime, or a crunchyroll subscription, so they’ll pull it up on jellyfin. It’s easy to remember for them because it’s just jellyfin.mydomain.com
They don’t know anything about how the backend gets the movies/tv shows, just that they go to ombi, and it shows up on jellyfin if they want something ;)
Gosh, that’s cute. Probably how I’ll end up too. Right now I’m not ready to let friends use my services. I already have friends and family on adguard and vaultwarden, that’s enough responsibility for now.
Architecture looks dope
Hope you’ve safeguarded your setup by writing a provisoning script in case anything goes south.
I had to reinstall my server from scratch twice and can’t fathom having to reconfigure everything manually anymore
Nope, don’t have that yet. But since all my compose and config files are neatly organized on the file system, by domain and then by service, I tar up that entire docker dir once a week and pull it to the homelab, just in case.
How have you setup your provisioning script? Any special services or just some clever batch scripting?
Old school ansible at first, then I ditched it for Cloudbox (an OSS provisioning script for media server)
Works wonders for me but I believe it’s currently stuck on a deprecated Ubuntu release
Possible for a dark mode version XD? excalidraw can do that.
Of course! here you go: https://files.catbox.moe/hy713z.png. The image has the raw excalidraw data embedded, so you can import it to the website like a save file and play around with the sorting if need be.
Thanks for the dark mode link!!
I was also going to mention draw.io
Thank you 🫶
How do you like crowdsec? I’ve used it on a tiny VPS (2 vcpu / 1 GB RAM) and it hogs my poor machine. I also found it to have a bit of learning curve, compared to fail2ban (which is much simpler, but dosen’t play well with Caddy by default).
Would be happy to see your Caddy / Crowdsec configuration.
The crowdsec agent running on my homelab (8 Cores, 16GB RAM) is currently sitting idle at 96.86MiB RAM and between 0.4 and 1.5% CPU usage. I have a separate crowdsec agent running on the Main VPS, which is a 2 vCPU 4GB RAM machine. There, it’s using 1.3% CPU and around 2.5% RAM. All in all, very manageable.
There is definitely a learning curve to it. When I first dove into the docs, I was overwhelmed by all the new terminology, and wrapping my head around it was not super straightforward. Now that I’ve had some time with it though, it’s become more and more clear. I’ve even written my own simple parsers for apps that aren’t on the hub!
What I find especially helpful are features like
explain, which allow me to pass in logs and simulate which step of the process picks that up and how the logs are processed, which is great when trying to diagnose why something is or isn’t happening.The crowdsec agent running on my homelab is running from the docker container, and uses pretty much exactly the stock configuration. This is how the docker container is launched:
crowdsec: image: crowdsecurity/crowdsec container_name: crowdsec restart: always networks: socket-proxy: ports: - "8080:8080" environment: DOCKER_HOST: tcp://socketproxy:2375 COLLECTIONS: "schiz0phr3ne/radarr schiz0phr3ne/sonarr" BOUNCER_KEY_caddy: as8d0h109das9d0 USE_WAL: true volumes: - /mnt/user/appdata/crowdsec/db:/var/lib/crowdsec/data - /mnt/user/appdata/crowdsec/acquis:/etc/crowdsec/acquis.d - /mnt/user/appdata/crowdsec/config:/etc/crowdsecThen there’s the Caddyfile on the LabProxy, which is where I handle banned IPs so that their traffic doesn’t even hit my homelab. This is the file:
{ crowdsec { api_url http://homelab:8080 api_key as8d0h109das9d0 ticker_interval 10s } } *.mydomain.com { tls { dns cloudflare skPTIe-qA_9H2_QnpFYaashud0as8d012qdißRwCq } encode gzip route { crowdsec reverse_proxy homelab:8443 } }Keep in mind that the two machines are connected via tailscale, which is why I can pass in the crowdsec agent with its local hostname. If the two machines were physically separated, you’d need to expose the REST API of the agent over the web.
I hope this helps clear up some of your confusion! Let me know if you need any further help with understanding it. It only gets easier the more you interact with it!
don’t worry, all credentials in the two files are randomized, never the actual tokens
Thanks for the offer! I might take you up on that :-) If you have a Matrix handle and hang out in certain rooms, please DM me and I’ll
harassreach out to you there.Hm, I have yet to mess around with matrix. As anything fediverse, the increased complexity is a little overwhelming for me, and since I am not pulled to matrix by any communities im a part of, I wasn’t yet forced to make any decisions. I mainly hang out on discord, if that’s something you use.
Somehow I only had issues with CrowdSec. I used it with Traefik but it would ban me and my family every time they used my selhosted matrix instance. I could not figure out why and it even did that when I tried it on OPNSense without the Traefik bouncer…
I have crowdsec on a bunch of servers. It’s great and I love that I’m feeding my data to the swarm.
Acronyms, initialisms, abbreviations, contractions, and other phrases which expand to something larger, that I’ve seen in this thread:
Fewer Letters More Letters DNS Domain Name Service/System HTTP Hypertext Transfer Protocol, the Web HTTPS HTTP over SSL IP Internet Protocol Plex Brand of media server package SSH Secure Shell for remote terminal access SSL Secure Sockets Layer, for transparent encryption TCP Transmission Control Protocol, most often over IP VPN Virtual Private Network VPS Virtual Private Server (opposed to shared hosting) k8s Kubernetes container management package nginx Popular HTTP server
11 acronyms in this thread; the most compressed thread commented on today has 15 acronyms.
[Thread #473 for this sub, first seen 2nd Feb 2024, 05:25] [FAQ] [Full list] [Contact] [Source code]
Remeber, the more boxes you have, the more advanced you are as an admin! Once you do his job for money, the challenge is the exact opposite. The less parts you have, the better. The more vanilla they are, the better.
Absolutely! To be honest, I don’t even want to have countless machines under my umbrella, and constantly have consodilation in mind - but right now, each machine fulfills a separate purpose and feels justified in itself (homelab for large data, main VPS for anything thats operation critical and cant afford power/network outages and so on). So unless I find another purpose that none of the current machines can serve, I’ll probably scale vertically instead of horizontally (is that even how you use that expression?)
What software did you use to make this image? Its very well done
Thank you! It’s done in excalidraw.com. Not the most straightforward for flowcharts, took me some time to figure out the best way to sort it all. But very powerful once you get into the flow.
If you’re feeling funny, you can download the original image from the catbox link and plug it right back into the site like a save file!
Now just gotta understand everything beyond… Jellyfin haha
Draw.io is also pretty good or lucidcharts
I saved this! Yeah, it seems like a lot of work, but I got inspired again (I had a slight self-hosting burnout and nuked my raspberry setup ~year ago) so I appreciate it. :) Can I ask what hardware you run this on? edit: I just wanted to ramble some more: I just fired up my rPI4 again just last week, setup it with just as barebone VPS with wireguard, samba, jellyfin and pi-hole+unbound (as to not burn myself again :D )
Glad to have gotten you back into the grind!
My homelab runs on an N100 board I ordered on Aliexpress for ~150€, plus some 16GB Corsair DDR5 SODIMM RAM. The Main VPS is a 2 vCPU 4GB RAM machine, and the LabProxy is a 4 vCPU 4GB RAM ARM machine.
What VPS service do you use/recommend and what’s your monthly cost?
I use Hetzner, mainly because of their good uptime, dependable service and being geographically close to me. Its a “safe bet” if you will. Monthly cost, if we’re not counting power usage by the homelab, is about 15 bucks for all three servers.
I have taken a picture and shall study it
I’ve seen Caddy mentioned a few times recently, what do you like about it over other tools?
In addition to the other commenter and their great points, here’s some more things I like:
- ressource efficient: im running all my stuff on low end servers, and cant afford my reverse proxy to waste gigabytes of RAM (kooking at you, NPM)
- very easy syntax: the Caddyfile uses a very simple, easy to remember syntax. And the documentation is very precise and quickly tells me what to do to achieve something. I tried traefik and couldn’t handle the long, complicated tag names required to set anything up.
- plugin ecosystem: caddy is written in go, and very easy to extend. There’s tons of plugins for different functionalities, that are (mostly) well documented and easy to use. Building a custom caddy executable takes one command.
I think the two of you have convinced me to check it out! It is sounding pretty great, so thank you in advance.
I can answer this one, but mainly only in reference to the other popular solutions:
- nginx. Solid, reliable, uncomplicated, but. Reverse proxy semantics have a weird dependency on manually setting up a dns resolver (why??) and you have to restart the instance if your upstream gets replaced.
- traefik. I am literally a cloud software engineer, I’ve been doing Linux networking since 1994 and I’ve made 3 separate attempts to configure traefik to work according to its promises. It has never worked correctly. Traefik’s main selling point to me is its automatic docker proxying via labels, but this doesn’t even help you if you also have multiple VMs. Basically a non-starter due to poor docs and complexity.
- caddy. Solid, reliable, uncomplicated. It will do acme cert provisioning out of the box for you if you want (I don’t use that feature because I have a wildcard cert, but it seems nice). Also doesn’t suffer from the problems I’ve listed above.
I feel so relieved reading that about traefik. I briefly set that up as a k8s ingress controller for educational purposes. It’s unnecessarily confusing, brittle, and the documentation didn’t help. If it’s a pain for people in the industry that makes me feel better. My next attempt at trying out k8s I’ll give Kong a shot.
I really like solid, reliable, and uncomplicated. The fun part is running the containers and VMs, not spending hours on a config to make them accessible.
I have traefik running on my kubernetes cluster as an ingress controller and it works well enough for me after finagling it a bit. Fully automated through ansible and templated manifests.
Heh. I am, as I said, a cloud sw eng, which is why I would never touch any solution that mentioned ansible, outside of the work I am required to do professionally. Too many scars. It’s like owning a pet raccoon, you can maybe get it to do clever things if you give it enough treats, but it will eventually kill your dog.
Care to share some war stories? I have it set up where I can completely destroy and rebuild my bare metal k3s cluster. If I start with configured hosts, it takes about 10 minutes to install k3s and get all my services back up.
Sure, I mean, we could talk about
- dynamic inventory on AWS means the ansible interpreter will end up with three completely separate sets of hostnames for your architecture, not even including the actual DNS name. if you also need dynamic inventory on GCP, that’s three completely different sets of hostnames, i.e. they are derived from different properties of the instances than the AWS names.
- btw, those names are exposed to the ansible runtime graph via different names i.e.
ansible_inventoryvs some other thing, based on who even fuckin knows, but sometimes the way you access the name will completely change from one role to the next. - ansible-vault’s semantics for when things can be decrypted and when they can’t leads to completely nonsense solutions like a yaml file with normal contents where individual strings are encrypted and base64-encoded inline within the yaml, and others are not. This syntax doesn’t work everywhere. The opaque contents of the encrypted strings can sometimes be treated as traversible yaml and sometimes cannot be.
- ansible uses the system python interpreter, so if you need it to do anything that uses a different Python interpreter (because that’s where your apps are installed), you have to force it to switch back and forth between interpreters. Also, the python setting in ansible is global to the interpreter meaning you could end up leaking the wrong interpreter into the role that follows the one you were trying to tweak, causing almost invisible problems.
- ansible output and error reporting is just a goddamn mess. I mean look at this shit. Care to guess which one of those gives you a stream which is parseable as json? Just kidding, none of them do, because ansible always prefixes each line.
- tags are a joke. do you want to run just part of a playbook? --start-at. But oops, because not every single task in your playbook is idempotent, that will not work, ever, because something was supposed to happen earlier on that didn’t. So if you start at a particular tag, or run only the tasks that have a particular tag, your playbook will fail. Or worse, it will work, but it will work completely differently than in production because of some value that leaked into the role you were skipping into.
- Last but not least, using ansible in production means your engineers will keep building onto it, making it more and more complex, “just one more task bro”. The bigger it gets, the more fragile it gets, and the more all of these problems rears its head.
-
Dynamic inventory. I haven’t used it on a cloud api before but I have used it against kube API and it was manageable. Are you saying through kubectl the node names are different depending on which cloud and it’s not uniform? Edit: Oh you’re talking about the VMs doh
-
I’ve tried ansible vault and didn’t make it very far… I agree that thing is a mess.
-
Thank god I haven’t ran into interpreter issues, that sounds like hell.
-
Ansible output is terrible, no argument there.
-
I don’t remember the name for it, but I use parameterized template tasks. That might help with this? Edit: include_tasks.
-
I think this is due to not a very good IDE for including the whole scope of the playbook, which could be a condemnation of ansible or just needing better abstraction layers for this complex thing we are trying to manage the unmanageable with.
-
Fully agree to this summary. traefik also gave me a hard time initially, but once you have the quirks worked out, it works as promised.
Caddy is absolutely on my list as an alternative, but the lack of docker label support is currently the main roadblocker for me.
May I present to you: Caddy but for docker and with labels so kind of like traefik but the labels are shorter 👏 https://github.com/lucaslorentz/caddy-docker-proxy
Jokes aside, I did actually use this for a while and it worked great. The concept of having my reverse proxy config at the same place as my docker container config is intriguing. But managing labels is horrible on unraid, so I moved to classic caddy instead.
Nice catch and thanks for sharing. Will definitely check it out.
@oh_gosh_its_osh @xantoxis for #k8s solution though I think traefik has advantage of providing configuration via CRDs, no?
deleted by creator
I see everyone else have already chimed in on whats so great about Caddy (because it is!), one thing that has been a thorn in my side though is the lack of integration of fail2ban since Caddy has moved on from the old common log format and moved on to more modern log formats. So if you want to use a IPS/IDS, you’ll have to either find a creative hack to make it work with fail2ban or rely on more modern (and resource heavier) solutions such as crowdsec.
You can install the log transformer plugin for Caddy and have it produce a readable log format for fail2ban: https://github.com/caddyserver/transform-encoder
I had this setup on my VPS before I moved to a k3s setup. I will take a look at how to migrate my fail2ban setup to the new server.
Cool, thanks for this! As a user of Caddy through Docker, I suppose I need to find a way to build a docker image to be able to do this?
Sometimes new simple technologies makes things simple - but only as long as one intends to follow how they are used… 🙃
I think so, but if you check the official image you can definitely find out how to include custom plugins in it. I think the documentation might mention a thing or two about it too.
What is seedbox? Is it part of the homelab or a service like the VPSs?
its basically a VPS that comes with torrenting software preinstalled. Depending on hoster and package, you’ll be able to install all kinds of webapps on the server. Some even enable Plex/Jellyfin on the more expensive plans.
How do you do the sshfs mount, tracker and search queries? Is that over tailscale?
The rclone mount works via SSH credentials. Torrent files and tracker searches run over simple HTTPS, since both my torrent client and jackett expose public APIs for these purposes, so I can just enter the web address of these endpoints into the apps running on my homelab.
Sidenote, since you said
sshfs mount: I tried sshfs, but has significantly lower copy speeds than withrclone mount. Might have been a misconfiguration, but it was more time efficient to use rclone than trying to debug my sshfs connection speed.I have noticed very slow speeds with sshfs as well. I’ll have to give rclone mount over ssh a try. Thanks!
What is the proxy in front of crowdsec for?
If you’re referring to the “LabProxy VPS”: So that I don’t have to point a public domain that I (plan to) use more and more in online spaces to my personal IP address, allowing anyone and everyone to pinpoint my location. Also, I really don’t want to mess with the intricacies of DynDNS. This solution is safer and more reliable than DynDNS and open ports on my router thats not at all equipped to fend off cyberspace attacks.
If you’re referring to the caddy reverse proxy on the LabProxy VPS: I’m pointing domains that I want to funnel into my homelab at the external IP of the proxy VPS. The caddy server on that VPS reads these requests and reverse-proxies them onto the caddy-port from the homelab, using the hostname of my homelab inside my tailscale network. That’s how I make use of the tunnel. This also allows me to send the crowdsec ban decisions from the homelab to the Proxy VPS, which then denies all incoming requests from that source IP before they ever hit my homelab. Clean and Safe!
“pinpoint” is a bit hyperbolic. Country, state and maybe city can be pretty good, at least in the US.
It’s fine if that’s important to you to hide, but entirely unnecessary for most people.
Maybe. But I’ve read some crazy stories on the web. Some nutcases go very far to ruin an online strangers day. I want to be able to share links to my infrastructure (think photos or download links), without having to worry that the underlying IP will be abused by someone who doesn’t like me for whatever reason. Maybe that’s just me, but it makes me sleep more sound at night.
Thanks, but I meant the HAProxy in your homelab.
Oh, that! That app proxies the docker socket connections over a TCP channel. Which provides a more granular control over what app gets what access to specific functionalities of the docker socket. Directly mounting the socket into an app technically grants full root access to the host system in case of a breach, so this is the advised way to do it.









{kind=link}
{kind=link}
{kind=link}