

I’m trying to train a machine learning model to detect if an image is blurred or not.
I have 11,798 unblurred images, and I have a script to blur them and then use that to train my model.
However when I run the exact same training 5 times the results are wildly inconsistent (as you can see below). It also only gets to 98.67% accuracy max.
I’m pretty new to machine learning, so maybe I’m doing something really wrong. But coming from a software engineering background and just starting to learn machine learning, I have tons of questions. It’s a struggle to know why it’s so inconsistent between runs. It’s a struggle to know how good is good enough (ie. when should I deploy the model). It’s a struggle to know how to continue to improve the accuracy and make the model better.
Any advice or insight would be greatly appreciated.
View all the code: https://gist.github.com/fishcharlie/68e808c45537d79b4f4d33c26e2391dd
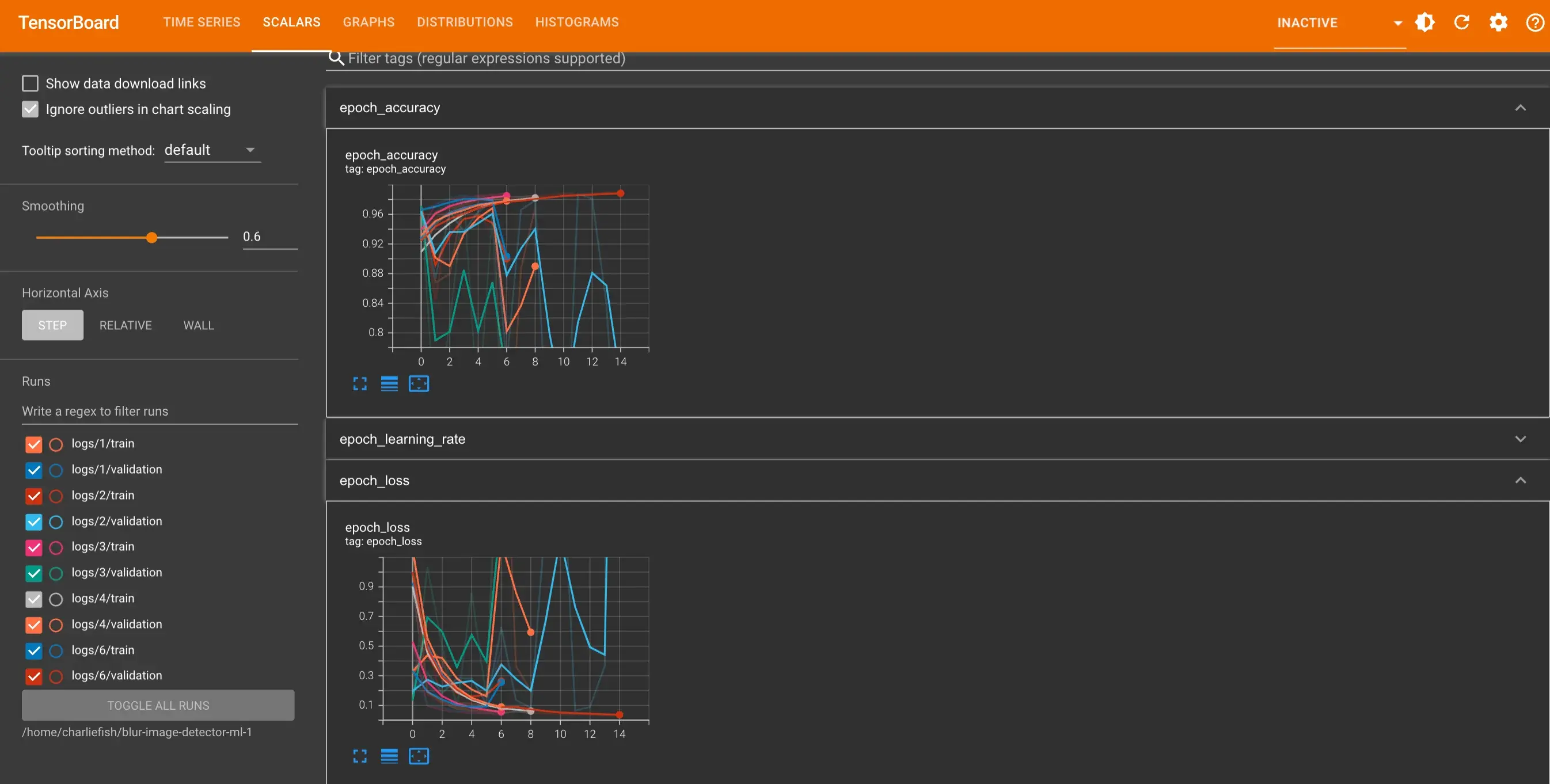
No problem, happy to help. In a lot of cases, even direct methods couldn’t reach 100%. Sometimes the problem definition, combined with just regular noise in you input, will mean that you can have examples that have basically the same input, but different classes.
In the blur-domain, for example, if one of your original “unblurred” images was already blurred (or just out of focus) it might look pretty indistinguishable from “blurred” image. Then the only way for the net to “learn” to solve that problem is by overfitting to some unique value in that image.
A lot of machine learning is just making sure the nets are actually solving your problem rather than figuring out a way to cheat.