
LGTM. Though do people really code with ligatures turned on?
Edit: Ok so there are some big advocates of ligatures, I’m going to have to give them a second chance. I’ll try for a week, and either way that Fira Code font looks great.
I was skeptical of ligatures at first, too, it took me awhile to warm up to it. But yeah, love me some Fira Code now.
That’s neat, so TIL ligature in code do actually have a strong following
I always do, I love having ligatures
Having ≠ looks much nicer then !=
Ah! You see, in my mind != looks nicer than ≠. Haha
That’s why those exist
Yes, I use Fira Code myself
When you realize 90% of programming is reading, then you’ll end up embarking on a journey to make code more readable. At some point you fall in love with ligatures.
Ligatures make code way easier to read, especially if you’re using lambdas or a language with different comparison operators than “normal”.
Yes, with Iosevka font
Long live Fixedsys! My favourite font since before time.
I found a version with ligatures. Love the thick equally spaced characters. Makes stuff so nice to read.
python -c 'print((61966753*385408813*916167677<<2).to_bytes(11).decode())'how?
$ python >>> b"Hello World".hex() '48656c6c6f20576f726c64' >>> 0x48656c6c6f20576f726c64 87521618088882533792115812 $ factor 87521618088882533792115812 87521618088882533792115812: 2 2 61966753 385408813 916167677perl -le 'use bignum;print+pack"H22",(61966753*385408813*916167677<<2)->to_hex()'Alas, Perl doesn’t bignum by default
Umm… someone explain this code please?
Bit shift magic.
My guess is that all the individual characters of Hello World are found inside the 0xC894 number. Every 4 bits of
xshows where in this number we can find the characters for Hello World.You can read x right to left. (Skip the rightmost 0 as it’s immediately bit shifted away in first iteration)
3 becomes H 2 becomes e 1 becomes l 5 becomes o
etc.
I guess when we’ve exhausted all bits of x only 0 will be remaining for one final iteration, which translates to !
Too readable. You’ve gotta encode the characters as the solutions of a polynomial over a finite field, implemented with linear feedback on the bit shifts. /s
I understand that the characters are probably encoded into that number, but I’m struggling to understand that C/C++ code.
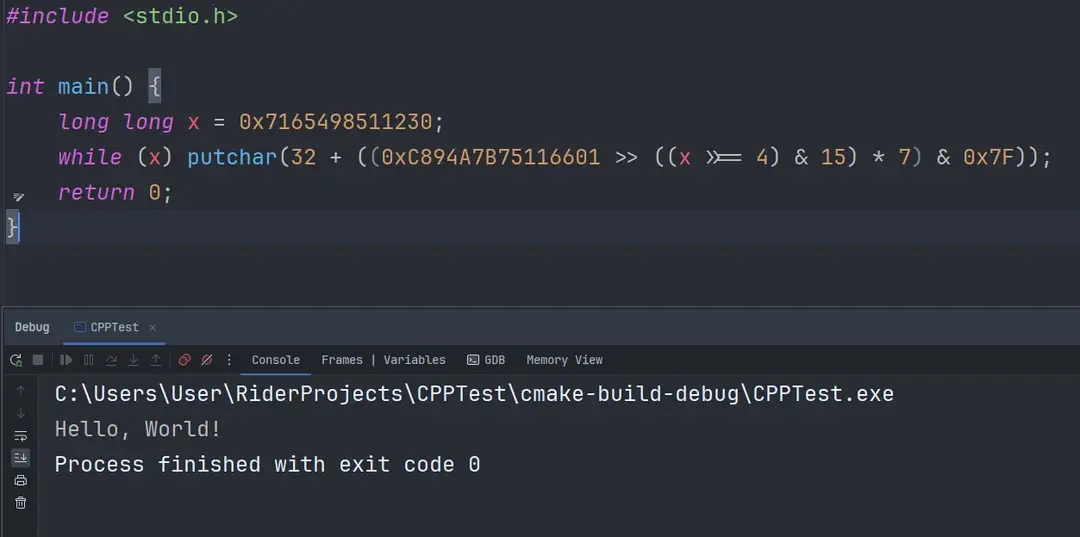
#include <stdio.h> int main() { Long long x = 0x7165498511230; while (x) putchar(32 + ((0xC894A7875116601 >> ((x >>= 4) & 15) * 7) & 0x7F)); return 0; }Might be wrong on a few things here as I haven’t done C++ in a while, but my understanding is this. I’m sure you can guess that this is just a very cheekily written while loop to print the characters of “Hello, World!” but how does it work? So first off, all ASCII characters have an integer value. That 32 there is the value for the space character. So depending on what ((0xC894A7875116601 >> ((x >>= 4) & 15) * 7) & 0x7F)) evaluates down into you’ll get different characters. The value for “H” for example is 72 so that first iteration we know that term somehow evaluated to the number 40 as 72 - 32 = 40.
So how do we get there? That big number, 0xC894A7875116601 is getting shifted right some number of bits. Let’s start evaluating the parenthesis. (X >>= 4) means set x to be itself after bit shifting it right by 4 bits then whatever that number is we bitwise AND it with 15 or 1111 in binary. This essentially just means each iteration we discard the rightmost digit of 0x7165498511230, then pull out the new right most digit. So the first iteration the ((x >>= 4) & 15) term will evaluate to 3, then 2, then 1, then 1, etc until we run out of digits and the loop ends since effectively we’re just looking for x to be 0.
Next we take that number and multiply it by 7. Simple enough, now for that first iteration we have 21. So we shift that 0xC894A7875116601 right 21 bits, then bitwise AND that against 0x7F or 0111 1111 in binary. Just like the last time this means we’re just pulling out the last 7 bits of whatever that ends up being. Meaning our final value for that expression is gonna be some number between 0 and 127 that is finally added to 32 to tell us our character to print.
There are only 10 unique characters in “Hello, World!” So they just assigned each one a digit 0-9, making 0x7165498511230 essentially “0xdlroW ,olleH!” The first assignment happens before the first read, and the loop has a final iteration with x = 0 before it terminates. Which is how the “!” gets from one end to the other. So they took the decimal values for all those ASCII characters, subtracted 32 then smushed them all together in 7 bit chunks to make 0xC894A7875116601 the space is kinda hidden in the encoding since it was assigned 9 putting it right at the end which with the expression being 32 + stuff makes it 0 and there’s an infinitely assumed parade of 0s to the left of the C.
Thank you.
32 is ASCII space, the highest number you need is 114 for r (or 122 for z if you want to be generic), that’s a range of 82 or 90 values.
The target string has 13 characters, a long long has 8 bytes or 16 nibbles – 13 fits into 16 so nibbles (the
(x >>= 4) & 15) it is. Also the initial x happens to have 13 nibbles in it so that makes sense. But a nibble only has 16 values, not 82, so you need some kind of compression and that’s the rest of the math, no idea how it was derived.If I were to write that thing I’d throw PAQ at it it can probably spit out an arithmetic coding that works, and look even more arcane as you wouldn’t have the obvious nibble steps. Or, wait, throw NEAT at it: Train it to, given a specific initial seed, produce a second seed and a character, score by edit distance. The problem space is small enough for the approach to be feasible even though it’s actually a terrible use of the technique, but using evolution will produce something that’s utterly, utterly inscrutable.
What is that weird >>=== symbol? Looks like a cross breed between C and JavaScript here.
It’s a the right shift assignment operator so
x >>= 4right shifts x by 4 and assigns the result back to x. The code editor is displaying single double wide symbol (ligature) instead of the three character long operator>=, I discovered today these are in fact well loved by some coders.Yeah… I love them. Makes my != look like ≠
If someone likes it but doesn’t know where to find it, FiraCode does linea tires really good IMO
I totally thought because of how long the equals looked, it was multiple equals characters, not just >>= lol. That’s what got me confused. Don’t think these are things I’d personally use but each to their own preferences right xD
I guess it’s a special kind of character called a ligature. They apparently are characters for combined operators. So in this case it seems to just be >>= all as one character?
It is exactly that. Some people really like them, others do not (me included). You usually need to go a little out of your way to get a font that supports ligatures for your editor.
As long as I don’t have to maintain it.
(Who tf downvoted this? The “legacy code” lobby?)
Convenience link for people interested in the ligatures:
The best Hello World I saw used a random library. Because there’s no true random without hardware, the author figured out the correct seed to write Hello World with “random” characters. I’ve used that to show junior devs that random in programming doesn’t mean truly random.






{kind=link}