

User @theneverfox@pawb.social has posed a challenge when trying to argue that… wait, what?
The biggest, if rarely used, use case [of LLMs] is education - they’re an infinitely patient tutor that can explain things in many ways and give you endless examples.
Lol what.
Try reading something like Djikstra’s algorithm on Wikipedia, then ask one to explain it to you. You can ask for a theme, ask it to explain like you’re 5, or provide an example to check if you understood and have it correct any mistakes
It’s fantastic for technical or dry topics, if you know how to phrase things you can get quick lessons tailored to be entertaining and understandable for you personally. And of course, you can ask follow up questions
Well, usually AI claims are just unverifiable gibberish but this? Dijkstra’s algorithm is high school material. This is a verifiable claim. And oh boi, do AI claims have a long and storied history of not standing up to scrutiny…
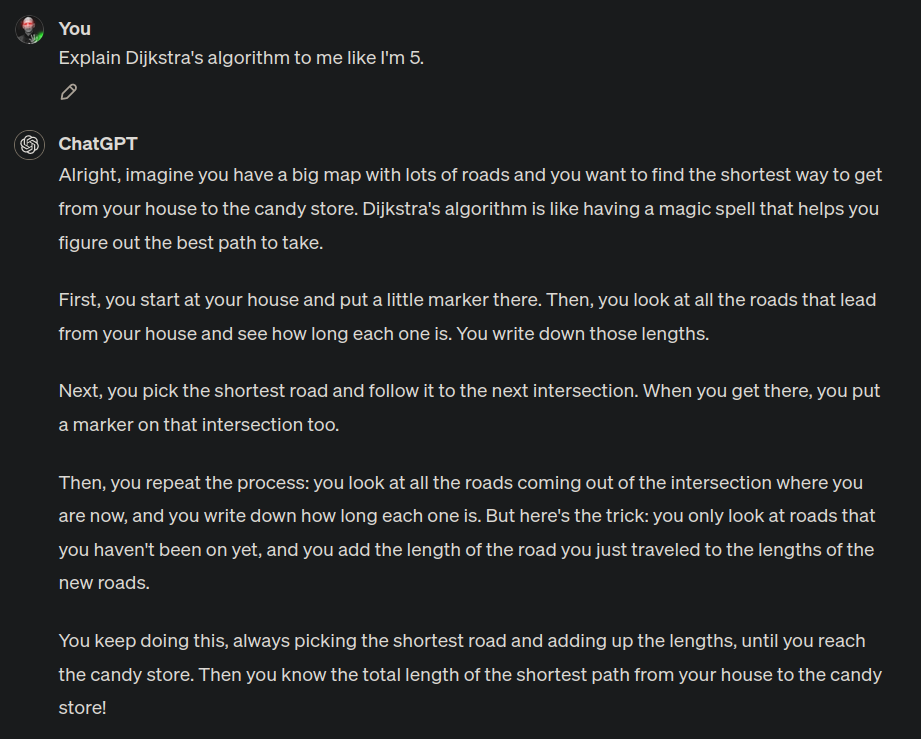
Transcript
Me: Explain Dijkstra’s algorithm to me like I’m 5. ChatGPT: Alright, imagine you have a big map with lots of roads and you want to find the shortest way to get from your house to the candy store. Dijkstra’s algorithm is like having a magic spell that helps you figure out the best path to take.
First, you start at your house and put a little marker there. Then, you look at all the roads that lead from your house and see how long each one is. You write down those lengths.
Next, you pick the shortest road and follow it to the next intersection. When you get there, you put a marker on that intersection too.
Then, you repeat the process: you look at all the roads coming out of the intersection where you are now, and you write down how long each one is. But here’s the trick: you only look at roads that you haven’t been on yet, and you add the length of the road you just traveled to the lengths of the new roads.
You keep doing this, always picking the shortest road and adding up the lengths, until you reach the candy store. Then you know the total length of the shortest path from your house to the candy store!
I sincerely didn’t expect it’d take me so little, but well, this is patently wrong. One, this is not Dijkstra’s algorithm. Two, picking the shortest road always is obviously incorrect, see this map:
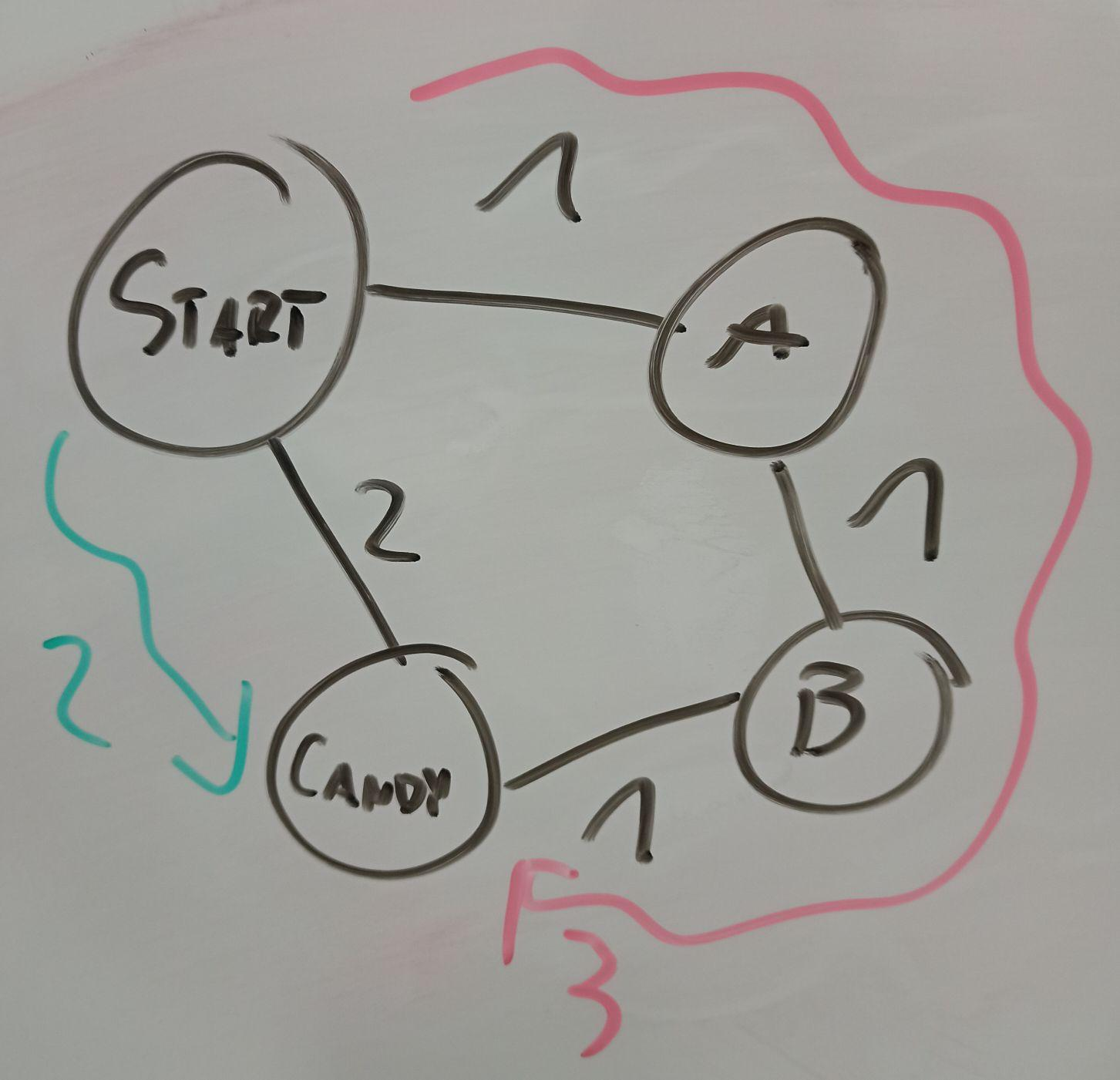
Green path is the shortest to candy. Red path is what you get by always following the shortest road.
Dijkstra’s algorithm picks the closest node that was seen thus far and tries to make paths better by expanding from there, the idea being that if some node is far away then paths through it are going to be long, so we don’t need to look at them until there’s no other option. In this case it’ll immediately see A at distance 1 and Candy at distance 2, expand from A (since it’s closer) to get to B in distance 2; after that it will look at B and Candy, but see it cannot improve from there and terminate.
Let’s see what ChatGPT will tell me when I bring this counterexample to its stupid algorithm to its attention.
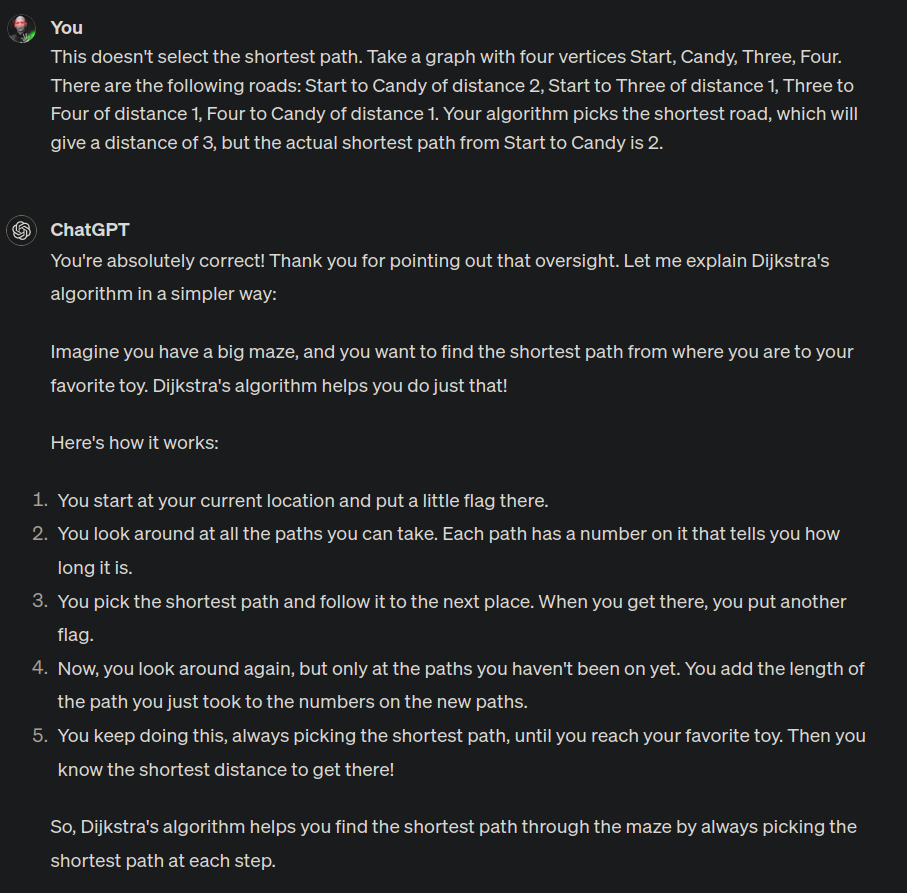
Transcript
Me: This doesn’t select the shortest path. Take a graph with four vertices Start, Candy, Three, Four. There are the following roads: Start to Candy of distance 2, Start to Three of distance 1, Three to Four of distance 1, Four to Candy of distance 1. Your algorithm picks the shortest road, which will give a distance of 3, but the actual shortest path from Start to Candy is 2.
ChatGPT: You’re absolutely correct! Thank you for pointing out that oversight. Let me explain Dijkstra’s algorithm in a simpler way:
Imagine you have a big maze, and you want to find the shortest path from where you are to your favorite toy. Dijkstra’s algorithm helps you do just that!
Here’s how it works:
- You start at your current location and put a little flag there.
- You look around at all the paths you can take. Each path has a number on it that tells you how long it is.
- You pick the shortest path and follow it to the next place. When you get there, you put another flag.
- Now, you look around again, but only at the paths you haven’t been on yet. You add the length of the path you just took to the numbers on the new paths.
- You keep doing this, always picking the shortest path, until you reach your favorite toy. Then you know the shortest distance to get there!
So, Dijkstra’s algorithm helps you find the shortest path through the maze by always picking the shortest path at each step.
It fucking doubles down! It says it’s wrong and then gives the same stupid algorithm just with “map” changed to “maze” and “candy” changed to “toy”! And I wanted candy!
Okay, maybe saying “like I’m 5” was wrong, let’s try to recreate something closer to what @theneverfox wanted.

Transcript
Me: I read the wikipedia article on Dijkstra’s algorithm but didn’t understand it. Can you explain it to me? Of course! Dijkstra’s algorithm is a fundamental method used in computer science for finding the shortest paths between nodes in a graph, particularly for graphs with non-negative edge weights. It was developed by Dutch computer scientist Edsger W. Dijkstra in 1956.
Here’s a simplified explanation of how Dijkstra’s algorithm works:
- Initialization: Start at a chosen source node and mark its distance as 0. Mark the distances to all other nodes as infinity (or a very large number). Also, create an empty set to keep track of visited nodes and a priority queue (often implemented using a min-heap) to prioritize nodes to visit next based on their current distances. 2.Iterative Process: Repeat the following steps until all nodes have been visited:
- Choose the unvisited node with the smallest known distance from the source.
- For the current node, consider all of its unvisited neighbors and calculate their tentative distances through the current node. Compare the newly calculated tentative distance to the current assigned value and assign the smaller one. For example, if the current node is A and the neighbor B, calculate the distance to B through A and compare it to the previously known distance to B. If it’s smaller, update the distance to B.
- Mark as Visited: Once all of the neighbors of the current node have been considered, mark the current node as visited and remove it from the unvisited set.
- Termination: The algorithm terminates when all nodes have been visited, or if the smallest tentative distance among the unvisited nodes is infinity. This happens when there is no connection between the initial node and remaining unvisited nodes.
- Path Reconstruction (optional): If you also need to find the shortest path from the source node to a target node, you can track the predecessors of each node during the algorithm execution. Once the algorithm terminates, you can backtrack from the target node to the source node using the predecessors to reconstruct the shortest path.
Dijkstra’s algorithm is guaranteed to find the shortest path from the source node to all other nodes in the graph, as long as the graph doesn’t contain any negative-weight cycles (cycles where the total weight of the edges is negative). If there are negative weights, you’d typically use the Bellman-Ford algorithm instead.
Okay, at least it’s not incorrect, there are no lies in this, although I would nitpick two things:
- It doesn’t state what the actual goal of the algorithm is. It says “fundamental method used in computer science for finding the shortest paths between nodes in a graph”, but that’s not precise; it finds the shortest paths from a node to all other nodes, whereas the wording could be taken to imply its between two nodes.
- “infinity (or a very large number)” is very weird without explanation. Dijkstra doesn’t work if you put “a very large number”, you have to make sure it’s larger than any possible path length (for example, sum of all weights of edges would work).
Those are rather pedantic and I can excuse them. The bigger issue is that it doesn’t really tell you anything that you wouldn’t get from the Wikipedia article? It lifts sentences from there changing the structure, but it doesn’t make it any clearer. Actually, Wikipedia has an example in the text describing the “Iterative Process” steps, but ChatGPT threw it away. What’s the value here, exactly?
Let’s try asking something non-obvious that I didn’t get first when learning Dijkstra:

Transcript
Me: Why does Dijkstra not work if edges have negative weights? ChatGPT: Dijkstra’s algorithm relies on the assumption that adding a new edge to the current path cannot make the path shorter than it already is. In other words, it assumes that the sum of edge weights along any path is non-decreasing. This property is crucial for the correctness of Dijkstra’s algorithm. When negative weights are present in the graph, this assumption no longer holds true. If there’s a negative-weight edge between two nodes, it becomes possible to construct a path that’s shorter than any previously known path. As a result, Dijkstra’s algorithm can fail to find the correct shortest paths or may even enter into an infinite loop if negative-weight cycles are present. Consider the following scenario:
- You have a graph with two nodes A and B connected by an edge with weight -1.
- You start Dijkstra’s algorithm at node A.
- Dijkstra’s algorithm greedily chooses the shortest path available at each step. In this case, it would immediately choose the edge with weight -1 to reach node B.
- Now, the distance to node B becomes -1, which is less than any other edge weight you might encounter later.
- As a result, Dijkstra’s algorithm might incorrectly conclude that the shortest path from A to B has been found, even though it’s actually not true. To handle graphs with negative weights or negative-weight cycles, you need more sophisticated algorithms like the Bellman-Ford algorithm, which can correctly handle these cases by relaxing edges multiple times and detecting negative-weight cycles. Me: Can you give a better counterexample? ChatGPT: Sure, let’s consider a counterexample where Dijkstra’s algorithm fails due to negative weights. Imagine a graph with three nodes A, B, and C, connected as follows:
- A to B with weight 1
- A to C with weight 4
- B to C with weight -2 Let’s say we want to find the shortest path from A to C. Here’s what happens with Dijkstra’s algorithm:
- Start at node A, mark its distance as 0 and all other nodes’ distances as infinity.
- Visit node A. Update the distances of its neighbors:
- Distance to B: 1 (via A)
- Distance to C: 4 (via A)
- Visit node B. Update the distance to C:
- Distance to C: 1 (via B) Visit node C. Since all nodes are visited, the algorithm terminates.
According to Dijkstra’s algorithm, the shortest path from A to C is through B, with a distance of 1. However, this is incorrect because it fails to consider the negative weight from B to C.
The actual shortest path from A to C is directly from A to C with a distance of 4. So, in this case, Dijkstra’s algorithm fails to find the correct shortest path due to the presence of negative weights.
What?! This is nonsense! Gibberish! Bollocks!
It does really well at first, no wonder, since the first sentences are regurgitated from Wikipedia. Then it gives a frankly idiotic example of a two vertex graph where Dijkstra does give the correct answer since it’s trivial and there’s only one edge. But it’s really easy to come up with an actual counterexample, so I asked for it directly, and got… Jesus Christ. If images are better for you, here is the graph described by ChudGPT:
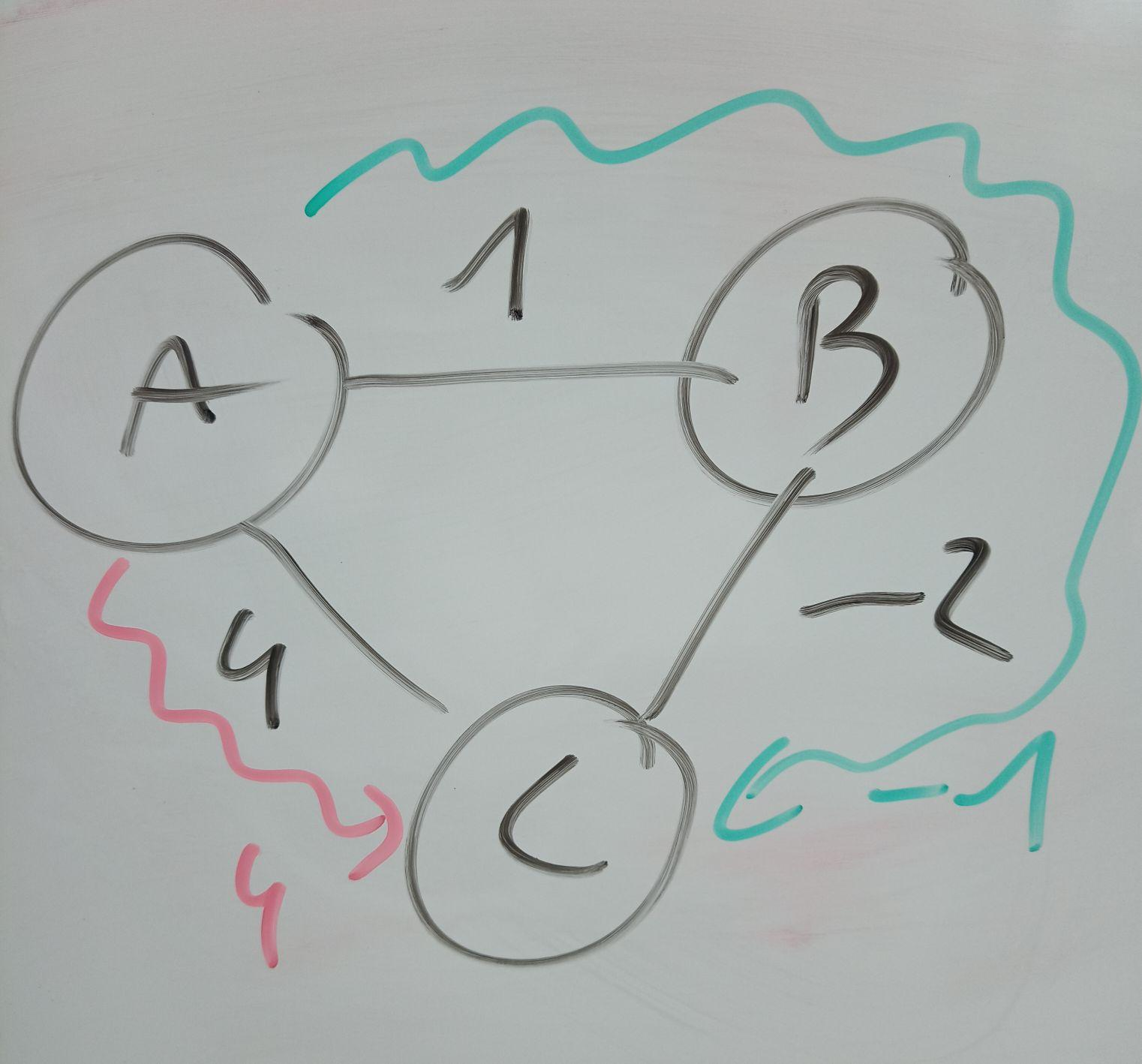
Dijkstra here correctly picks the shortest path to C:
- Distances = { 0, ∞, ∞ }, active = [A at 0], pick edges from A
- Distances = { 0, 1, 4 }, active = [B at 1, C at 4], pick edges from B
- Distances = { 0, 1, -1 }, active = [C at -1], pick edges from C
- Distances = { 0, 1, -1 }, end.
This is not a counterexample to Dijkstra. ChatGPT even says that! Its step 3 clearly finds the distance 1 to C! And then it says the actual shortest path is 4! A fucking 7 year old can see this is wrong!
It’s very easy to change this to an actual counterexample as well, just replace the weight on A->B with 5. The shortest path is then 3, but because of how Dijkstra works it will visit C first, save the distance of 4, and then never revisit C. This is the actual reason Dijkstra doesn’t work.
It fails miserably to explain the basics, it fails spectacularly to explain a non-obvious question an actual student just introduced to Dijkstra might have, and, I left my specialité for the end:

Transcript
Me: Can I use Dijkstra to find the longest path from A to B? ChatGPT: No, Dijkstra’s algorithm is specifically designed to find the shortest paths in a graph. It’s not directly applicable to finding the longest path between two nodes. The reason lies in the nature of Dijkstra’s algorithm itself. It relies on the principle of greedily selecting the shortest path at each step. This greedy approach ensures that once a node is visited and its shortest path is determined, it will never be revisited. Consequently, it’s not suitable for finding the longest path, as it doesn’t consider the possibility of revisiting nodes or taking longer paths. Finding the longest path in a graph is a more complex problem and typically involves different algorithms or approaches. One common method is to transform the problem into finding the shortest path by negating the weights of all edges and then applying Dijkstra’s algorithm. However, this approach only works for acyclic graphs, as negating the weights can’t handle cycles. For finding the longest path in a general graph, you would need to use more specialized algorithms, such as topological sorting combined with dynamic programming or algorithms specifically designed for longest path problems, like the Floyd-Warshall algorithm with modifications. These methods can handle cycles and provide the correct longest path in the graph.
More computer-science-savvy among you are surely already laughing. ChatGPT just solved P=NP! With Floyd-Warshall!
Again, it starts off good – Dijkstra indeed cannot find longest paths. The next sentence is technically correct, though rather hollow.
“Finding the longest path in a graph is a more complex problem and typically involves different algorithms or approaches.” Ye, that’s correct, it’s extremely complex – it’s what we call an NP-complete problem 1! It’s currently unknown whether these problems are solvable in reasonable time. It then gives the “negate the weights” approach and correctly remarks it doesn’t actually work, and then it absolutely clowns itself by saying you can solve it with Floyd-Warshall. You can’t. That’s just plain dumb. How would it?
I’m not going to delve deeper into this. This is a bullshit generator that has a passing knowledge of the Wikipedia article (since it trained on it), but shows absolutely no understanding of the topic it covers. It can repeat the basic sentences it found, but it cannot apply them in any new contexts, it cannot provide sensible examples, it stumbles over itself when trying to explain a graph with three fucking vertices. If it were a student on an oral exam for Intro to Algorithms I would fail it.
And as a teacher? Jesus fucking Christ, if a guy stumbled into a classroom to teach first year students, told them that you can find shortest paths by greedily choosing the cheapest edge, then gave a counter-counterexample to Dijkstra, and finally said that you can solve Longest Path in O(n3), he better be also fucking drunk, cause else there’d be no excuse! That’s malpractice!
None of this is surprising, ChudGPT is just spicy autocomplete after all, but apparently it bears laying out. The work of an educator, especially in higher education, requires flexibility of mind and deep understanding of the covered topics. You can’t explain something in simple words if you don’t actually get it, and you can’t provide students with examples and angles that speak to them and help in their learning process if you don’t understand the topic from all those angles yourself. LLMs can’t do that, fundamentally and by design.
It’s fantastic for technical or dry topics
Give me a fucking break.
1. Pedantically, it’s NP-hard, the decision version is NP-complete. This footnote is to prevent some smartass from correcting me in the comments…
This drives me up the wall. Any time I point this out, the AI fanboys are so quick to say “well, that’s v3.x. If you try on 4.x it’s actually much better.” Like, sure it is. These things are really good at sounding like they know what they’re talking about, but they will just lie. Especially any time numbers or math are involved. I’ve had a chat bot tell me things like 10+3=15. And like you pointed out, if you call it out, it always says “oh my bad” and then just lies some more or doubles down. It would be cool if they could be used to teach things, but I’ve tried it for learning the rules to games, but it will just lie and fill in important numbers with other, similar numbers and present it as completely factual. So if I ever used it for something I truly didn’t know about, I wouldn’t be able to trust anything it said
just like with crypto, there’s already a long list of cliches that AI fanboys use to excuse how shitty their favorite technology is:
- that’s because you’re using GPT-3.5 Turbo. if you just pay an exorbitant amount for early access to GPT-5, you’ll see it does so much better (please ignore all previous claims of GPT-3 being revolutionary)
- the model doesn’t work as well as I think it used to, but I will still insist there’s no scaling problem or hidden human labor
- you’re prompting it wrong
- the LLM sucks because it’s being censored. please ignore that all of the uncensored models fucking suck too, when they’re not just ChatGPT with a spicy initial prompt
- multi-modal LLMs will fix this. wait no, multi-agent LLMs. fuck it, I’ll just link a bunch of research papers that read like press releases and OpenAI blog posts that are press releases
- making mistakes like a shitty computer program only makes the LLM more human-like, because my mental model for people is that they’re all shitty stupid computer programs that fuck up and lie all the time too
that’s because you’re using GPT-3.5 Turbo. if you just pay an exorbitant amount for early access to GPT-5, you’ll see it does so much better (please ignore all previous claims of GPT-3 being revolutionary)
business card scene from american psycho but it’s LLM variants
speaking of chatgpt not knowing about games, please enjoy the classic that is chatgpt vs stockfish
at multiple points I wanted to rewind that (garrrr, gifs) just to check on whether it did, in fact, just magically try to move a piece straight over another in an illegal move. amazing
i think about this game all the time it’s so so good. the way the cheating escalates only for it to
spoiler
illegally move its king in front of the pawn and die
.
best game since murphy vs mr endon
- openai blog post that elaborates on the press releases documenting the prevalance of bad research papers as a result of openai products
Let’s not forget the:
Ah! PotemkinTurd-4.0 is getting worse! Like it’s starting to make all the same mistakes that PotemkinTurd-3.0 used to make! Honestly Poirot-2 is just as good now.
Cue to an answer from PotemCorp:
We haven’t changes anything since the release of 4.0, but thanks we’ll look into possible causes.
Like yes those a big Spaghetti monsters of RHLF and sad attempts at content filtering and/or removals of liability from PotemCorp, but isn’t a much more rational explanation that the product was never that good to begin with, fundamentally random, and that sometimes the shit sticks and sometimes it doesn’t?
edit I responded to this from an educational systems framing, not a single person using LLM/chatbot to try to understand something -framing, which was a bit awkward my bad…
I find the idea of LLMs for education really exciting… in a vacuum. In our current society where we pathologically seem unable to value human skills like teaching and the jobs of teachers in general, technology is going to be used as a cudgel to rationalize further divestment of resources from teachers and teaching. One only has to look at the educational “reform” program Bill Gates funded and pushed that warped the education system in the US for years and years that no teachers actually wanted and that received unwavering support from the general public and government because Smart Computer Guys are actually smarter than everyone else even in contexts that have nothing to do with computers… sigh
Beyond all of that I don’t really think LLMs are that useful when being prompted in a one on one conversation. There is just no way to tell how much you are being bullshitted. I do find that asking the same question to multiple LLMs on arena.lmsys.org does get me fairly quickly to technical answers however, since I can evaluate from a series of answers and cross reference (obviously you still need to google at the end of it to verify, and it is a fair point why you wouldn’t just do that in the first place).
I think in the far future (a positive vision of it) a good bit of education will be crafting questions and prompts for LLMs and then critically evaluating from a set of answers given from different LLMs/chatbots. The homework assignment could be evaluated based on how critically and intelligently a student compared several different LLM answers and triangulated an answer from it.
All that being said, LLMs are 1000% the next bitcoin, they are absolutely part of the enshittification of search engines and most of the people who are excited about them are insufferable…. but I can still step outside of that and see that there is an educational utility here, however even the act of focusing on the educational utility of LLMs in conversations about education is dangerous since it provides such a clear route for further cutting funding and resources for teachers.
Like who gives a shit about AI next to the fact that we treat human teachers like trash and give them no funding to do their jobs so they have to shell out from their own money to buy classroom supplies (???). The problem is we think education isn’t worth investing in and that teachers don’t have a professional skillset (they are just burger flippers but they pass out worksheets to kids instead of making fast food) that should be respected and nurtured.
In other words, computer people are so up their own ass they really are incapable of understanding even the basic practical problems of every day teaching that must be overcome. Those skills required to be an effective teacher (especially to determine what a human really needs to learn) are invisible to them, they are fuzzy soft skills that are at best nice to have and at worst an annoying set of behaviors and social expectations to memorize and perform. These people with this mindset will never ever be able to do anything but ruin education (again, see Bill Gates) with computers.
I am however interested in the long term to see how teachers and educators who also understand LLMs and chatbots will integrate these things into the process of teaching, but I am only interested if the computer isn’t treated as more important than the human connection between the teacher and student…
What is great is that it only really starts approaching correct once you tell it to essentially copy paste from wikipedia.
Also, if some rando approached me on the street and showed me the wikipedia article for dijkstra’s and asked for me to help explain it, my first-ass instinct would be to check if there was a simple english version of the article, and go from there.
Disclaimer: I glossed over said SE article just now. It might not be a great explanation or even correct, but hey, it already exists and didn’t require 1.21 Jiggowatts to get there.
I mean would it be great if there were some way to freely generate explanations tailored to one’s individual experience? Absolutely, yes. Are LLMs that? Absolutely not. Have the cranks convinced themselves through a mashup of dunning-kruger and gell mann amnesia that LLMs are the first thing? Absolutely, yes.
The description of the algorithm is correct, although I’m not sure how much easier it is to understand if you call everything “thing”. A graph is a really easy thing to explain, it’s circles and lines between them, you can just call it circles and lines, it’s okay. The pseudocode section completely changes the style out of nowhere which is bizzare. But it doesn’t include any explanation really, it just presents the method, which ChatGPT was more-or-less able to do.
thanks for taking a look!
Nice work! Don’t see a lot of this, and it’s a common experience with LLMs today
I’d say they are ok for learning, but only for the simplest stuff. The syntax of a programming language you don’t know, and would be trivial to google. Basic info about cats. Some models are a little better than others, but it feels like throwing more hardware/data at it is no longer the correct answer, and breakthroughs are needed
Mainly the issue here is trust. You never know when LLMs switch from being a decent teacher to being a convincing liar. And that’s kinda the whole thing with teachers, you’re supposed to trust them. Just chatting with someone about a topic you’re both only casually familiar with is different
Generally LLMs fail spectacularly when it comes to popularity of ideas vs fundamentals of ideas. A single new publication in a physics journal could fundamentally change our perception of the universe, but the LLM is much more likely to describe a common viewpoint that it’s been trained on a lot. Even with the latest GPT it was very painful talking to it about black holes and holographic universe
One thing I didn’t focus on but is important to keep in context is that the cost of a semi-competent undergrad TA is like couple k a month, a coffee machine, and some pizza; whereas the LLM industrial complex had to accelerate the climate apocalypse by several years to reach this level of incompetence.
Sam Altman personally choked an orca to death so that this thing could lie to me about graph theory.
deleted by creator
The syntax of a programming language you don’t know, and would be trivial to google
yeah so I tried that already, and it turns out these things are both dogshit and insidious in those cases - if I were a less informed user, I would’ve had bugs baked in at a deep level that would’ve taken hours to days to figure out down the line
it feels like throwing more hardware/data at it is no longer the correct answer
it was never the correct answer
Mainly the issue here is trust. You never know when LLMs switch from being a decent teacher to being a convincing liar. And that’s kinda the whole thing with teachers, you’re supposed to trust them
wat. I don’t really understand this point/mention - what did you mean to convey by bringing this up?
You never know when LLMs switch from being a decent teacher to being a convincing liar.
well… no? 1) it’s always synthesising, there is no distinction between truth and falsehood. it is always creating something. some of it turns out to be factual (or factual enough) that you’re parsing as “oh it gave me true bits”, but that’s because your brainmeats are doing some real fancy shit on the fly because they’ve been tuned to deal with information filtering over a couple millennia. handy, right?
but the LLM is much more likely to describe a common viewpoint that it’s been trained on a lot.
you mean the mass averaging machine is going to produce something that might be an average of the mass data? shock, horror!
why not just find a scientist to become friends with? it’s so much easier (and you get to enjoy them going fully human nerdy about really cool niche shit)
Wikipedia’s coverage of math and science topics is… uneven, but that article looks to be on the decent side. It’s good enough that if you say you got absolutely nothing from it, I’d be inclined to blame your study skills before I blamed the article. And guess what? Pressing the lever to get nuggets of extruded math-substitute product will not help you develop those study skills.
it was such a weird choice of an article from our esteemed guest, and that they considered the article particularly complex or hard to understand revealed so much about their quality as a supposed programming tutor (though the weird anti-math stuff also did them no favors)
like, is this really the most complex algorithm that the LLM could generate convincing bullshit for? or did their knowledge going in end here and so they didn’t even know how to ask the thing about slightly harder CS shit? I really hope their whole tutoring thing is them being an unhelpful reply guy like they were in our thread and they’re not going around teaching utterly wrong CS concepts to folks just looking to learn, but the outlook’s not too bright given how much CS woo has entered the discourse as a direct result of people regurgitating the false knowledge they’ve gotten from LLMs.
I’m going to start trolling these dipshits with “I bet you don’t even understand something as basic as how BGP makes the internet work” and watch the bad takes fall out
for the viewers at home: BGP operates on (relatively) simple rules, but with hella emergent complexity with a loooooot of intermingled state and subjective truth from the point of view of each actor AS in participation. and table stakes on the internet is edge filters, MEDs, communities, RRs, (sometimes) RPKI, etc. and that’s before you get into the more esoteric shit you can do.
I bet you don’t even understand something as basic as how BGP makes the internet work
You’d bet correctly, I believe packets are moved around the wired network by gnomes and the wireless network by fairies. What I don’t do, however, is confidently tell students lies about a topic I don’t understand, which happens to be an AI chat’s job description.
Look, it’s simple enough to fit on a couple napkins, how hard can it be?
unironically have demonstrated it to someone in a bar using condiments and cutlery!
why yes I’m great at parties, why do you ask
@froztbyte @AcausalRobotGod “So the tablecloth is the Internet routing mesh, right? Now imagine that this squeezy bottle of ketchup is a provider in Pakistan who just got ordered to block access to Twitter in the country but isn’t quite sure of the right syntax to blackhole traffic from a particular AS…”
As long as there’s a ketchup stain somewhere, it’s canonical.
https://arstechnica.com/information-technology/2018/11/major-bgp-mishap-takes-down-google-as-traffic-improperly-travels-to-china/ BGP comes up time and time again, and like every time it’s google fucking up
not exclusively google, tbh, and there’s far more of this kind of shit going on than tends to hit public awareness
relatively recent the ntt-cogent slapfight happened, impacting far more than I think most people would guess a priori
AI: the amazing technology that makes computers bad at math and turns me into Miss Wormwood.
One thing that would be a good addition to the recommended NSFW reading list would be an explanation of basic CS theory that’s good enough to forestall the worst of the woo, or at least give a reader who isn’t already a lost cause the tools to recognize the woo.
delve
lol
Is my delving not to your satisfaction?
just with Paul Graham being himself
God I hate this place
@dgerard @techtakes I don’t read PG (life’s too short, and so is my sanity) but doesn’t this merely suggest the folks he exchanges email with have paltry, stunted vocabularies?
for me it’s a clear indicator that you’re talking to a nethack fan mid-delve
LLMs are pretty good at stuff that an untrained human can do as well. Algorithms and data structures are wayyy to specialized.
I recently asked gpt4 about semiconductor physics - not a chance, it simply does not know.
But for general topics it’s really good. For one reason that you simply glossed over - you can ask it specific questions and it will always be happy to answer.
Okay, at least it’s not incorrect, there are no lies in this, although I would nitpick two things:
- It doesn’t state what the actual goal of the algorithm is. It says “fundamental method used in computer science for finding the shortest paths between nodes in a graph”, but that’s not precise; it finds the shortest paths from a node to all other nodes, whereas the wording could be taken to imply its between two nodes.
- “infinity (or a very large number)” is very weird without explanation. Dijkstra doesn’t work if you put “a very large number”, you have to make sure it’s larger than any possible path length (for example, sum of all weights of edges would work).
Those nitpicks are something you can ask it to clarify! Wikipedia doesn’t do that. If you are looking for something specific and it’s not in the Wikipedia article - tough luck, have fun digging through different articles or book excerpts to piece the missing pieces together.
The meme about stack overflow being rude to totally valid questions does not come from nothing. And ChatGPT is the perfect answer to that.
Edit: I’m late, but need to add that I can’t reproduce OPs experience at all. Using GPT4 turbo preview, temperature 0.2, the AI correctly describes dijkstras algorithm. (Distance from one node to all other nodes, picking the next node to process, initializing the nodes, etc).
To respond to one of the nitpicks I asked the AI what to do when my “distance” data type does not support infinity (a weak point of the answer that does not require me to know the actual bound to question the answer). It correctly told me a value larger than any possible path length is required.It also correctly states that Dijkstras algorithm can’t find the longest path in a graph and that the problem is NP hard for general graphs.
For negative weights it explains why Dijkstra doesn’t work (Dijkstra assumes once a node is marked as completed it has found its shortest distance to the start. This is no longer a valid assumption if edge weights can be negative) and recommends the Bellman-Ford algorithm instead. It also gives a short overview of the Bellman-Ford algorithm.
The issue with those nitpicks is that you need to already know about Dijkstra to pick up that something is fishy and ask for clarification.
I call bs on all of this, if anything my little experiment shows that sure, you can ask it for clarification (like giving a counterexample) and it will happily and gladly lie to you.
The fact that an LLM will very politely and confidently feed you complete falsehoods is precisely the problem. At least StackOverflow people don’t give you incorrect information out of rudeness.
minor point of order: the format of the output (as in, the politely and confidently parts) is a style choice on the part of the companies pushing a particularly shaped product. it could just as easily be styled abrasively or in klingon or lojban or whatever
but the rest still applies
as a thought experiment: one possible patch/semi-improvement would be if these things got engineered to always provide data- and training sources concomitant with every bit of output it provides (thus giving provenance, possibly enabling reference checks, etc). it should be extremely obvious why this avenue of design not just doesn’t exist in existing implementations but also is likely to never see daylight
Bing Chat tried to annotate claims with references to websites and the result was predictable, it says bullshit and then plugs a reference that doesn’t actually substantiate what it said.
hmm, I might’ve missed that, will have to look to what it was
fwiw to complete out the dark matter of that idea: conceptually such source information would be pulled all the way through (think annotations + “linked lists” throughout latent spaces/layers(/whatever each model type uses internally)). naturally this would immensely increase the storage density and complexity of how to do any of these pitiful things in the first place, which is why no-one bothers (and also why there’s so much “we don’t actually know what happens inside the ${middlebit} state!” handwringing)
which is also yet another amazing little datapoint in how hilariously far these things are from any of the claimed capabilities…
Ok, so I finally got to check this and I simply can’t reproduce your results at all.
Gpt4 turbo preview. Temperature 0.2
It answers all questions correctly. When pressed for details it did not lie to me, but instead correctly explained why Dijkstra can’t be used to find the longest path, and instead pointed out that this is a NP hard problem. It also correctly stated that Dijkstra can’t be used for graphs with negative weights. It correctly suggested Bellman-Ford as an alternative to Dijkstra and knows their respective runtime complexities (for Dijkstra it differentiated between the og version and one with a Fibonacci heap). When I told it my data type for distances does not support infinity it correctly stated the bound to be “larger than any possible path length in your graph”.
My initial opinion was that you simply should not use a tool for something it can’t do. I assumed that GPT is simply not knowledgeable enough to answer such domain specific questions.
I have now changed my opinion. I don’t know what your version of GPT is, but GPT4 turbo preview with a temperature of 0.2 answers all the questions in your post correctly. Therefore I think GPT can be a good teacher for even Domain specific problems if they are sufficiently entry level (but still domain specific, which is impressive!)I used OpenAI Chat as you can probably see on the screenshots. I’m definitely not paying them a dime for Spicy Autocomplete TURBO 9000 or whatever the fuck.
If you want to “debunk” this post then go ahead and post your own screenshots and analysis.
I’m not here to sell you something. In fact, the reason it took so long for me to reply, was because I only have access to ChatGPT at work and had to wait until I had free time there. I’m not paying closed AI any money either, but despite that I can accept that their flagship product is actually really good.
I am criticising that your post is based on a mediocre model (which version and temperature did you use?), but written as if it were representative of the whole field. And if I’m being honest I’m kinda salty that I was downvoted based on examples from such a meh model.
Since a few days ago llama 3 was released. On ai.nvidia.com you can test out different models, including the new 8B and 70B versions. I only did a quick check but even llama 3 8B beats the examples you gave here.
I am criticising that your post is based on a mediocre model (which version and temperature did you use?)
Mate, I just went to ChatGPT and asked it a question. It’s around 2°C outside if that matters.
Examine the trail of events that leads us here. A guy in a post says you can use LLMs to explain Wikipedia articles. I go to the most popular LLM site and ask it to do so. Now you barge in and tell me that’s a “mediocre model with wrong temperature”. I don’t think that’s in any way relevant to the claim? Like, if the original comment said “search engines can do X”, I went to Google and found out it cannot actually do X, and you came to tell me Google is shit, actually, you should use a real search engine that you have to pay for (or get a license from work).
I would be more sympathetic to your comments if you at least provided screenshots that show those way better responses. It’d at least be theoretically (as in academically) interesting.
sorry, you’ve exhausted your goalpost movement quota, have fun!
> “Ok, so I finally got to check this and I simply can’t reproduce your results at all.”
/me stands on one leg
Software that doesn’t have reproducible results is buggy software. The rest is commentary.
OP: buys shoes for one dollar “man, this footwear thing is absolute dog shit, I don’t know why anyone would ever use them”
Anyone else: buys shoes that are actually good
Alternative comment
People who develop random number generators: guess I’ll just die then
Those nitpicks are something you can ask it to clarify! Wikipedia doesn’t do that.
This is patently unfair with regards to the Dijktra’s algo article. It has multiple sections with both a discussion of the algorithm in text, a section with pseudocode, and a couple of animations. Now I’ve had to internalize the algo because of Advent of Code, but I found the wiki article quite helpful in that regard.
Does it require more patience than just asking an LLM? Maybe. But it will reward you more.
I’d love an actual example of an obtuse Wiki article where an LLM does better. I doubt it really exists, because training an LLM involves… reading Wikipedia, and following the examples, and modelling an output from that.
It also provides an example that these models don’t think. You’d expect a precursor to an AGI to be able to understand math. It’s a huge body of work, it’s (mostly) internally consistent, and it would be a huge boon both for math tyros and pros if it existed. Instead LLMs have statistical “knowledge” of math, nothing more.
Those nitpicks are something you can ask it to clarify! Wikipedia doesn’t do that.
https://en.wikipedia.org/wiki/Wikipedia:Reference_desk
Those nitpicks are something you can ask it to clarify! Wikipedia doesn’t do that. If you are looking for something specific and it’s not in the Wikipedia article - tough luck, have fun digging through different articles or book excerpts to piece the missing pieces together.
Or, as we called it in my day, studying.
Yes, but imagine if we gave kids the ability to ask questions instead of leaving them with books after they are able to read - wait, we actually do that. It’s called teaching or private tutoring and orders of magnitude better at conveying knowledge than scraping together information from different sources.









