

I’m trying to train a machine learning model to detect if an image is blurred or not.
I have 11,798 unblurred images, and I have a script to blur them and then use that to train my model.
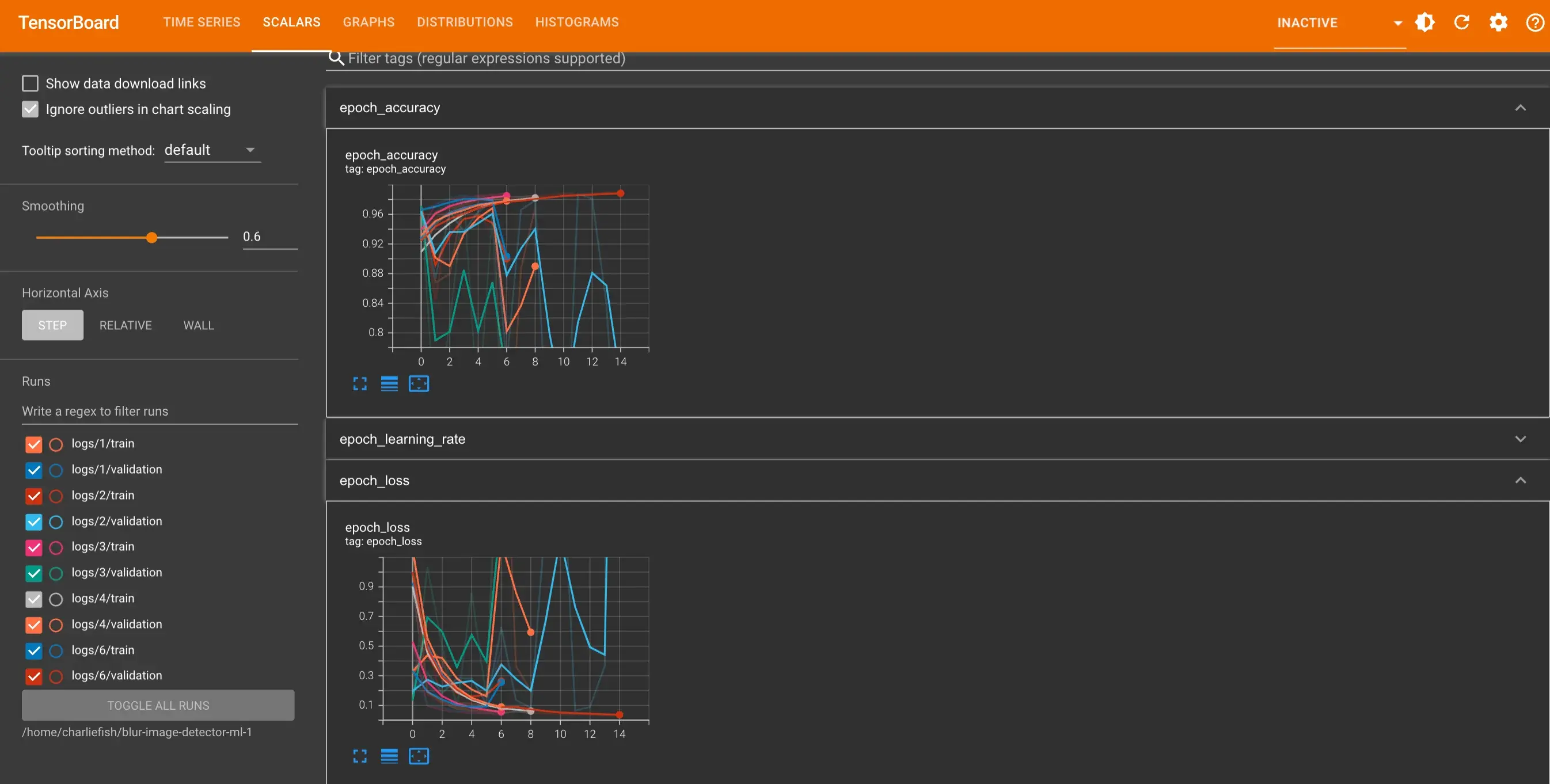
However when I run the exact same training 5 times the results are wildly inconsistent (as you can see below). It also only gets to 98.67% accuracy max.
I’m pretty new to machine learning, so maybe I’m doing something really wrong. But coming from a software engineering background and just starting to learn machine learning, I have tons of questions. It’s a struggle to know why it’s so inconsistent between runs. It’s a struggle to know how good is good enough (ie. when should I deploy the model). It’s a struggle to know how to continue to improve the accuracy and make the model better.
Any advice or insight would be greatly appreciated.
View all the code: https://gist.github.com/fishcharlie/68e808c45537d79b4f4d33c26e2391dd
It looks like 5x5 led to an improvement. Validation is moving with training for longer before hitting a wall and turning to overfitting. I’d try bigger to see if that trend continues.
The difference between runs is due to the random initialization of the weights. You’ll just randomly start nearer to solution that works better on some runs, priming it to reduce loss quickly. Generally you don’t want to rely on that and just cherry pick the one run that looked the best in validation. A good solution will almost always get to a roughly similar end result, even if some runs take longer to get there.
Got it. I’ll try with some more values and see what that leads to.
So does that mean my learning rate might be too high and it’s overshooting the optimal solution sometimes based on those random weights?
No, it’s just a general thing that happens. Regardless of rate, some initializations start nearer to the solution. Other times you’ll see a run not really make much progress for a little while before finding the way and then making rapid progress. In the end they’ll usually converge at the same point.
So does the fact that they aren’t converging near the same point indicate there is a problem with my architecture and model design?
That your validation results aren’t generally moving in the same direction as your training results indicates a problem. The training results are all converging, even though some drop at steeper rates. You won’t expect validation to match the actual loss value of training, but the shape should look similar.
Some of this might be the y-scaling overemphasizing the noise. Since this is a binary problem (is it blurred or not), anything above 50% means it’s doing something, so a 90% success isn’t terrible. But I would expect validation to end up pretty close to training as it should be able to solve the problem in a general way. You might also benefit from looking at the class distribution of the bad classifications. If it’s all non-blurred images, maybe it’s because the images themselves are pretty monochrome or unfocused.
Ok I changed the Conv2D layer to be 10x10. I also changed the dense units to 64. Here is just a single run of that with a Confusion Matrix.
I don’t really see a bias towards non-blurred images.
I’m not sure what the issue is, but I can’t see your confusion matrix. There’s a video player placeholder, but it doesn’t load anything.
Hard to tell whether the larger convolution was a bust or not. It’s got the one big spike away from the training loss, but every other epoch is moving downward with training, which looks good. Maybe try a few more runs, and if they commonly have that spike, try to give them longer to see if that loss keeps going downward to meet the training.
For efficiency you can also increase the convolutional stride. If you’re doing a 10x10 you can move by more than one pixel each stride. Since you’re not really trying to build local structures, going 5 or 10 pixels at a time seems reasonable.
Sorry for the delayed reply. I really appreciate your help so far.
Here is the raw link to the confusion matrix: https://eventfrontier.com/pictrs/image/1a2bc13e-378b-4920-b7f6-e5b337cd8c6f.webm
I changed it to
keras.layers.Conv2D(16, 10, strides=(5, 5), activation='relu'). Dense units still at 64.And in case the confusion matrix still doesn’t work, here is a still image from the last run.
EDIT: The wrong image was uploaded originally.
The new runs don’t look good. I wouldn’t have expected a half-width stride to cause issues though.
Are you sure the confusion matrix for the validation set? It doesn’t match a ~90% accuracy (previous solo run) or ~70-80% accuracy for the validation in the new runs.