stravanasu
- 201 Posts
- 680 Comments


 4·5 days ago
4·5 days agoA bit sad that Turing’s machine isn’t mentioned anywhere in their pages – but maybe I just missed the mention.
I’m not KokiKoi, but it’d be cool if you can help him. You can get in touch either through the Discord link at the bottom of his page: https://kokikoi.github.io/The-Koi-Site/ or maybe submitting an “issue” on their GitHub repo: https://github.com/KokiKoi/The-Koi-Site
Cheers!





 9·8 days ago
9·8 days ago“I can’t follow Mr. Trump,” McKellen added at the time. “I don’t always understand what he says and when I do, I have to admit later that I got it wrong because he changed his mind or changed his mind about what he said. He’s a very bad communicator, at least to me. Get more straightforward, Donald. And then we can take you seriously.”
 11·10 days ago
11·10 days agodeleted by creator
A final Community thing is that over the past five or so years, Mozilla has been turning away from it’s powerhouse, the Community. I have no idea why, but I can say that it’s a top down decision. At some point, some folk at a high level decided that Mozilla got to where it did on it’s own. It did not. The thing I was beating a drum about was that the folk working there were the lucky ones who got a paycheck, but most of their peers were folk who didn’t have a badge and a
@mozilla.comemail address. Leadership was convinced that the people in our Community were just customers, and maybe fans. This pissed off so, so many folk, and rightly so. They had given hours or years of effort and time without compensation, because they believed they were part of a larger effort. They felt betrayed because they were betrayed. I’m sure that someone probably had a reasonable argument about “how could we let all these outsiders have say?" or “I don’t like that those folk hate the amazing work we’re doing promoting lemony fresh bell bottoms (or whatever trend they were chasing)?” I dunno, boss, maybe the folk using your browser actually might have solid reasons of their own and might really appreciate things that don’t show up on LinkedIn top takes?

Now I understand, cheers. That’s a huge difference!
Admins decide which instances federate with each other
Apologies if I’m misunderstanding, but isn’t this true as also for Lemmy, Mastodon, and the Fediverse in general?

 3·17 days ago
3·17 days agohttps://libgen.li/librarian.php
Login with the anonymous credentials given there, then go to the “upload” tab. You can go there through a VPN.
This is also the answer given by AA.
 2·18 days ago
2·18 days agoI didn’t know, thank you for the info! I’ll explore his art, that cover is great indeed. 🙏
Can you recommend some novels by him? Cheers!
EU regimes can be even worse though:

Finally some Saitama action coming soon! 👊
Very clearly LLM-generated.
 11·22 days ago
11·22 days agoNot a surprise. It’s very clear that the USA are just Russia 2.
 23·26 days ago
23·26 days ago🤝 I download new music to check if I like it, and if I do then go over to Qobuz and buy it DRM-free and download the flac file, which is my flac file. Happy to support the musicians.









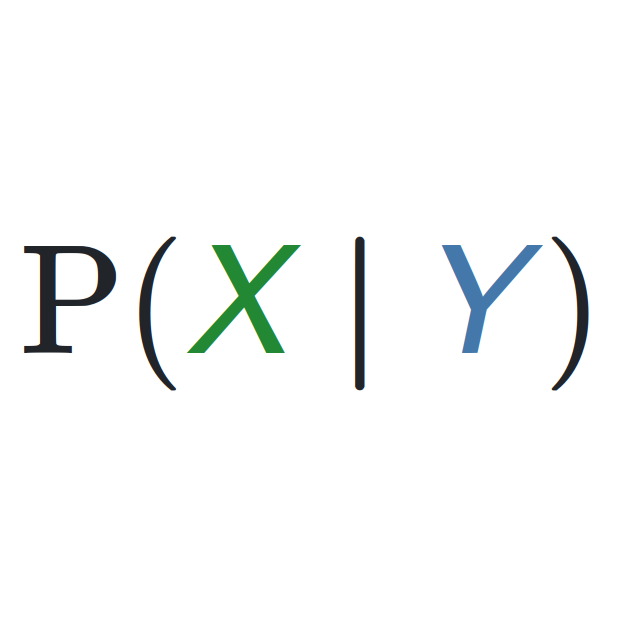
{kind=link}
{kind=link}
{kind=link}
If you have a Lenovo laptop, these are the keys:
Press Alt key (or whatever key maps to Alt, if you’ve made key remappings) and keep it pressed all the time, while doing as follows, where “Fn” is the function key:
You see the sequence gives “REISUB”.
When pressing keys or key combos, keep them pressed for a second or so. If you press a wrong key, restart from the beginning.
Good luck! 🍀💪