

My first experience with Lemmy was thinking that the UI was beautiful, and lemmy.ml (the first instance I looked at) was asking people not to join because they already had 1500 users and were struggling to scale.
1500 users just doesn’t seem like much, it seems like the type of load you could handle with a Raspberry Pi in a dusty corner.
Are the Lemmy servers struggling to scale because of the federation process / protocols?
Maybe I underestimate how much compute goes into hosting user generated content? Users generate very little text, but uploading pictures takes more space. Users are generating millions of bytes of content and it’s overloading computers that can handle billions of bytes with ease, what happened? Am I missing something here?
Or maybe the code is just inefficient?
Which brings me to the title’s question: Does Lemmy benefit from using Rust? None of the problems I can imagine are related to code execution speed.
If the federation process and protocols are inefficient, then everything is being built on sand. Popular protocols are hard to change. How often does the HTTP protocol change? Never. The language used for the code doesn’t matter in this case.
If the code is just inefficient, well, inefficient Rust is probably slower than efficient Python or JavaScript. Could the complexity of Rust have pushed the devs towards a simpler but less efficient solution that ends up being slower than garbage collected languages? I’m sure this has happened before, but I don’t know anything about the Lemmy code.
Or, again, maybe I’m just underestimating the amount of compute required to support 1500 users sharing a little bit of text and a few images?
The numbers are a little higher than you mention (currently ~3.2k active users). The server isn’t very powerful either, it’s now running on a dedicated server with 6 cores/12 threads and 32 gb ram. Other public instances are using larger servers, such as lemmy.world running on a AMD EPYC 7502P 32 Cores “Rome” CPU and 128GB RAM or sh.itjust.works running on 24 cores and 64GB of RAM. Without running one of these larger instances, I cannot tell what the bottleneck is.
The issues I’ve heard with federation are currently how ActivityPub is implemented, and possibly the fact all upvotes are federated individually. This means every upvote causes a federation queue to be built, and with a ton of users this would pile up fast. Multiply this by all the instances an instance is connected to and you have an exponential increase in requests. ActivityPub is the same protocol used by other federated servers, including Mastodon which had growing pains but appears to be running large instances smoothly now.
Other than that, websockets seem to be a big issue, but is being resolved in 0.18. It also appears every connected user gets all the information being federated, which is the cause for the spam of posts being prepended to the top of the feed. I wouldn’t be surprised if people are already botting content scrapers/posters as well, which might cause a flood of new content which has to get federated which causes queues to back up; this is mostly speculation though.
As it goes with development, generally you focus on feature sets first. Optimization comes once you reach a point a code-freeze makes sense, then you can work on speeding things up without new features breaking stuff. This might be an issue for new users temporarily, but this project wasn’t expecting a sudden increase in demand. This is a great way to show where inefficiencies are and improve performance is though. I have no doubt these will be resolved in a timely manner.
My personal node seems to use minimal resources, not having even registered compared to my other services. Looking at the process manager the postgres/lemmy backend/frontend use ~250MB of RAM.
For now, staying off lemmy.ml and moving communities to other instances is probably best. The use case of large instances anywhere near the scale of reddit wasn’t the goal of the project until reddit users sought alternatives. We can’t expect to show up here and demand it work how we want without a little patience and contributing.
Yup was just typing a comment to basically this effect. Federation adds a ton of overhead – you can still do things fairly efficiently, but every interaction having to fan out to (and fan in from!) many servers instead of like a single RDBMS is gonna cost you.
In all likelihood the code is not as efficient as it could be, but usually you get time to work those out gradually. A giant influx of users quickly turns “TODO: fix in the next six months” into “Oh god the servers are melting fuck fuck.”
That said, assuming the devs can get over this hump, I suspect using a compiled language will pay off long-term. Sure things will still be primarily IO-bound, but making things less CPU-bound is usually a good thing.
For some illustrative examples: Mastodon is in Ruby and hits dumb scaling limitations far more often than other fedi microblogs. Pleroma/Akkoma are Elixir (and BEAM is super well optimized for fast message passing/scaling/IO), Calckey (primarily Typescript) is moving some code to Rust, GoToSocial (Golang) is able to run in a fraction of the resources of Mastodon. The admins of one of the bigger tech instances recently announced they’re basically giving up on administrating Mastodon and are instead going to write a new server from scratch in a compiled language because it’s easier for them than scaling a Rails monolith.
TL;DR everything is IO-bound til it’s not.
I’m pretty sure the fediverse needs a new kind of node at some point. If we assume, that almost every larger instance is connected to almost every other larger instance directly, then there’s a ton of duplicated and very small messages.
There needs to be some kind of hub in-between to aggregate and route this avalanche. Especially if, like you wrote, every upvote is a message, the overhead (I/O, unmarshalling, etc) is huge.
You mean like centralizing the fediverse? Who hosts the hub? Who maintains it? In which country? Who pays for it?
Not a single hub, multiple ones.
Anyone can host a hub, federated instances can negotiate the intersection of hubs they both trust and then send traffic that way. That could mean, a single comment might be sent to, say, five hubs and each hub then forwards to 50 instances or so.
Since the hubs are rather simple, they can scale very easily and via cryptographic ratchets, all instances can make sure, they received the correct messages.
Hmm. Does the federation protocol only send information directly between servers, by that I mean that when something happens on A, does it send it to all other federated servers by itself?
If you could just proxy messages through other servers it would be an improvement. Essentially every instance would also be a hub. If you’re an instance A, connected to B and C, when B send you something you pass it onto C, instead of having C communicate with B directly.
In order to prevent spam you’d need whitelisting for the instances which you will act as a proxy for, and messages will have to be signed. Also, some protocol to discover the topology surrounding your server would be neat for optimizing delivery.
Hmm. Does the federation protocol only send information directly between servers, by that I mean that when something happens on A, does it send it to all other federated servers by itself?
As far as I know, yes. There’s probably a filter in the sense that an instance only gets update for relevant events, i.e. you don’t get messages for communities you’re not subscribed to.
If you could just proxy messages through other servers it would be an improvement. Essentially every instance would also be a hub. If you’re an instance A, connected to B and C, when B send you something you pass it onto C, instead of having C communicate with B directly.
That would essentially be the same concept, just wrapped into each instance. But it would a) put massive loads on these instances and b) need some entity/authority to find the optimal spanning tree in the network - and someone would need to define, what “optimal” means in this context.
I don’t think you need an optimal spanning tree. Proxying messages is basically just how Usenet works. You peer with a small number of other servers each party forwards messages in groups the other party is interested in.
As someone who used to run a Usenet server (20 years ago), I don’t think it’s a better system. The extra hops add a lot of questions related to moderation, filtering, censorship, trust, responsibility for forwarded content, and so on.
That’s why you’d need either a very closely to optimal spanning tree - or just direct intermediates (like a hub). Having messages bounce forever in the network would be far from ideal.
In any case, for everything above the actual message-handling layer, the aggregation should be transparent. That is, for moderation/filtering, etc. it shouldn’t matter, via which route the messages came to your instance.
Trust isn’t that hard either, if you sign messages (I have no idea if that’s already the case). Hubs would be no different from an ISP then.
Maybe I wasn’t clear enough above, but I would propose a very simple hub design. A hub receives messages that contain an envelope and a payload within the envelope, and then simply copy/repackage a bunch of payloads in new envelopes and send these to the connect message consumers. The actual payloads are not touch at all.
O(n*n) isn’t really scalable, so you either
a - have a small number of nodes total
b - have a small number of hubs with a larger number of leaf nodes.
Either way, there’s going to be some nodes that become more influential than others.
This is kinda how Usenet worked (well, still does). Rather than n*n federated connections, smaller providers tend to federate with central hubs that form backbones.
I think it makes sense for the fediverse as well.
Well said. Thanks for sharing your experience and those insightful links.
What specs are you running your instance on?
An old Chromebox G1 (i7-4600U and 8GB of ram) with a 128GB internal NGFF and external 1TB NVMe. It’s by no means powerful or expensive hardware. I’m also only receiving federated posts for my subscribed communities, and sending out these comments I write so it’s a lot lower workload than the larger instances.
Hosting a personal instance is the direction I want to go. That’ll be a winter project, though. It’s fishing/swimming/rowing/woodworking season now :)
Are there any general tips or hidden dangers you can share? Or is it as straightforward as just putting my nose into documentation and playing around a bit?
Right now there appears to be no more danger than hosting anything else. I run my services behind a reverse proxy to insulate my home LAN from the wider internet, but hooking anything up to the internet comes with potential dangers.
I personally wrote a helm chart for kubernetes to host the service, and a few more can be found here. I have some work to do yet on the helm chart but it closely mirrors the docker-compose file provided by the developers. Deployment of an instance should be a lot easier soon, with all the increased interest and contributions.
I can’t imagine what possessed them to use websockets other than “gee whiz websockets.”
Probably the same appeal as rust though: gee whiz.
Using less bandwidth, maybe? No need for exchanging the same HTTP headers over and over again if you’re using WebSockets. At least, that’s the benefit I can see on paper.
Seems like it didn’t work out so well in practice, though. I wonder why…
It could be the devs just like programming in Rust. It’s a nice language lol
I know I do. ¯\_(ツ)_/¯
Hi, programming.dev owner here. From what I’ve been seeing it’s a lot of memory issues. We were hitting swap which was causing massive disk io. You can see what happened with the disk io immediately after the upgrade to more memory.
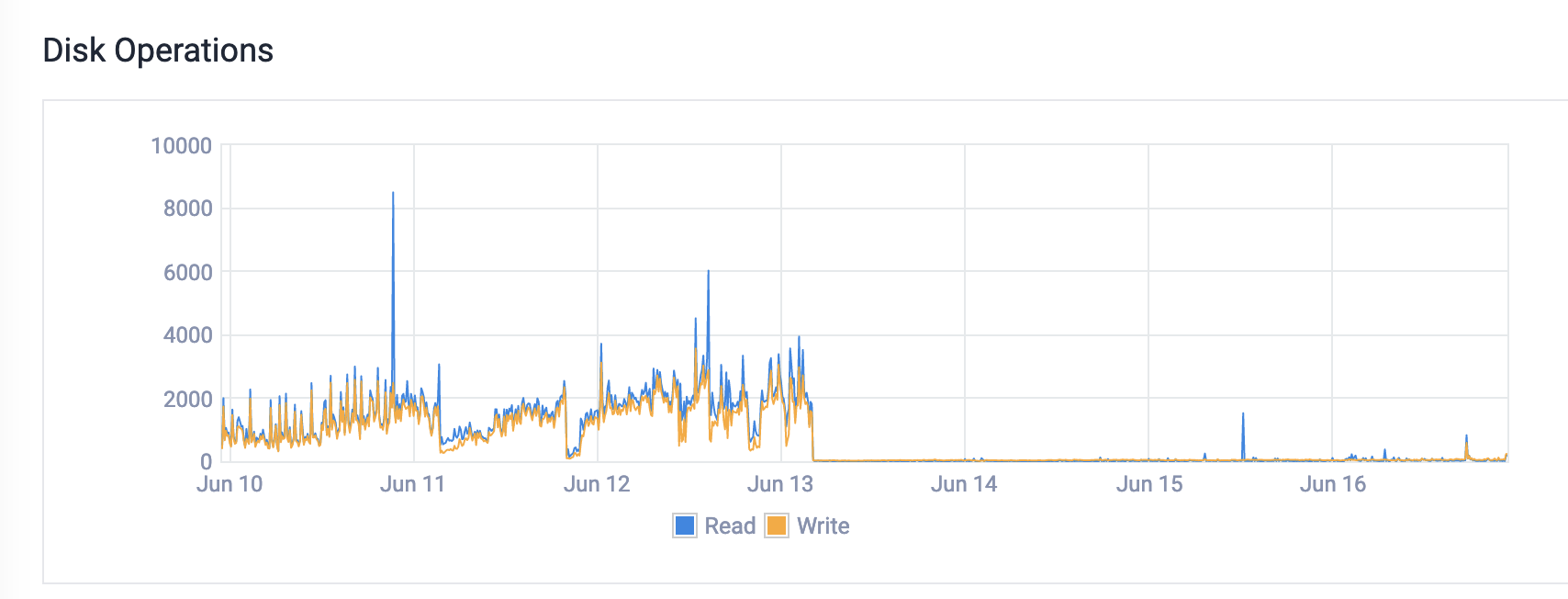 I know at least one reason is being resolved in this PR
I know at least one reason is being resolved in this PRWe were also having issues with the nginx config. There were some really weird settings that I don’t think were necessary. Finally, the federation is quite busy. So if someone subscribes to events from 10 different servers, we pull in every single event, even upvotes. There’s currently a lot of work being done around this stuff.
I don’t think Rust is the problem. I think it’s just a growth thing. Every platform has growth challenges, things grow in ways that you never expect. You might have thought that it was going to be IO constrained due to the federation, but in reality it’s memory constrained because memory is actually the most expensive thing to have on a server. etc.
So if someone subscribes to events from 10 different servers, we pull in every single event, even upvotes. There’s currently a lot of work being done around this stuff.
You mean like coalescing multiple events into a single message, or…? (I don’t know anything about ActivityPub, so apologies if this is a stupid question!)
correct. I’ve been looking for the thread to try and find it for you, but haven’t been having any luck. People have been discussing exactly that though, but it seems like it could cause some problems with vote faking. Anyway, it is being worked on!
Thank you for the insight. Fascinating. Also insane that ever upvote causes a flood of messages being distributed…
Any reason to use nginx versus something like Envoy? Like, I really like nginx, but Envoy’s xDS API is really great for on-the-fly changes. I also think it might scale better and have more relevant default values. I’m just not sure if Lemmy ties into nginx in some way, or if you’re purely using it as a reverse proxy.
I’ll note that most of my Envoy experience is from using it with k8s and a custom ingress controller, where my org handles millions of requests per second (across many Envoy pods). Deploying it standalone might make it less fun.
Nginx is part of the lemmy-ansible install. I’ve never heard of Envoy though. if you’re interested in helping out you can always join the discord. We also set up a matrix room, but it doesn’t have as much discussion in it yet. https://app.element.io/#/room/!hmRRJzTsXkNAGIDXNu:matrix.org
I would say that it’s extremely unlikely.
Websites in general are never limited by raw code execution, they are mostly limited by IO. Be that disk IO as files are read and written, database IO as you need to execute complex queries to gather all the data to build the user timeline, and network IO to transfer data to and from the user. For decentralized social media like Kbin or Lemmy its even more IO limited as each instance needs to go back and forth to other instances to keep up-to-date data.
Websites usually benefit much more from caching and in-memory databases to keep frequently used data in fast storage.
This is why simple, high level, object oriented, garbage collected languages have become so common. All the CPU performance penalties they incur don’t actually affect the website performance.
Not relevant to lemmy (yet), but this does break down a bit at very large scales. (Source: am infra eng at YouTube.)
System architecture (particularly storage) is certainly by far the largest contributor to web performance, but the language of choice and its execution environment can matter. It’s not so important when it’s the difference between using 51% and 50% of some server’s CPU or serving requests in 101 vs 100 ms, but when it’s the difference between running 5100 and 5000 servers or blocking threads for 101 vs 100 CPU-hours per second, you’ll feel it.
Languages also build up cultures and ecosystems surrounding them that can lend themselves to certain architectural decisions that might not be beneficial. I think one of the major reasons they migrated the YouTube backend to C++ isn’t really anything to do with the core languages themselves, but the fact that existing C++ libraries tend to be way more optimized than their Python equivalents, so we wouldn’t have to invest as much in developing more efficient libraries.
It is fairly relevant to lemmy as is. Quite a few instances have ram constraints and are hitting swap. Consider how much worse it would be in python.
Currently most of the issues are architectural and can be fixed with tweaking how certain things are done (i.e., image hosting on an object store instead of locally).
That’s correct. I wonder if YouTube still uses Python to this day.
Not saying there isn’t a difference in language performance, but for most world problems the architecture and algorithms matter more than the language for performance. Unless you’re in a very constrained environment such as lower end smartphones or embedded systems.
I wonder if YouTube still uses Python to this day
We do not.
Also this makes you think (assuming it’s true lol): https://www.reddit.com/r/Lemmy/comments/14h965f/comment/jpdemet
In lemmy’s case, my perusal of the DB didn’t really suggest that the queries would be that complex and I suspect that moving it to a higher performance NoSQL DB might be possible, but I’d have to take a look at a few more queries to be sure.
I wonder if this could be made to work with Aerospike Community Edition…
Obviously it could be more effort than it’s worth though.
The issues I’ve seen more are around images. Hosting the images on an object store (cloudflare r2, s3) and linking there would reduce a lot of federation bandwidth, as that’s probably cause higher ram/swap usage too.
pict-rs supports storing in object stores, but when getting/serving images, it still serves through the instance as the bottleneck IIRC. That would do quite a bit to free up some resources and lower overall IO needed by the server.
Ehhhhhhh. Using a relational database for Lemmy was certainly a choice, but I don’t think it’s necessarily a bad one.
Within Lemmy, by far the most expensive part of the database is going to be comment trees, and within the industry the consensus on the best database structure to represent these is… well, there isn’t one. The efficiency of this depends way more on how you implement it within a given database model than on the database model itself. Comment trees are actually a pretty difficult problem; you’ll notice a lot of platforms have limits on comment depth, and there’s a reason for that. Getting just one level of replies to work efficiently can be tricky, regardless of the choice of DBMS.
Looking at the schema Lemmy uses, I see a couple opportunities to optimize it down the road. One of the first things I noticed is that comment replies don’t seem to be directly related back to the top-level post, meaning you’re restricted to a breadth-first search of the comment tree at serving time. Most comments will be at pretty shallow depths, so it sometimes makes sense to flatten the first few levels of this structure so you can get most relevant comments in a single query and rebuild the tree post-fetching. But this makes nomination (i.e. getting the “top 100” or whatever comments to show on your page) a lot more difficult, so it makes sense that it’s currently written the way it is.
If it’s true (as another commenter said) that there’s no response caching for comment queries, that’s a much bigger opportunity for optimization than anything else in the database.
One benefit of using rust for webservers in general is that it’s possible to have a consistently lower latency compared to GCd langues: discord mentions this in their article about migrating to rust from go: https://discord.com/blog/why-discord-is-switching-from-go-to-rust
Another difference between rust and e.g. python is that rust expects you to invest more time to get code that’s runnable in the first place, but likely more well optimized and correct.
In my experience from writing rust, the language pushes you to write more efficient code compared to python because it makes things like copying visible and also because it’s easier to reason about memory usage compared to garbage collection which means that you’re more likely to have a useful model of the performance cost of various things while you’re programming.
It’s possible that a hypothetical lemmy written in python would have allowed the devs to do some big picture optimizations that they haven’t had the time to do yet in the rust version, so for the time being it might be slower than a python alternative.
Rust is likely to catch up though: eventually the rust version will probably also have this optimization while the python version has to resort to make smaller optimizations that the rust version already had in the first version of the code or that you get for free from the language.
I would like to point out that this article from Discord could be considered outdated these days. This comparison is using a old version of Go, that in recent years got a optimization on the GC and now would have much lower spikes than those showed in the article
Still, Rust surely will give you a higher performance and lower latency than Python
I mean, comparing it to Python is kinda unfair as Rust is closer to C and Python is one of the slowest languages out there. There is a whole spectrum of languages between Rust and Python. The final reason was probably that the devs were comfortable enough with Rust.
One benefit of using rust for webservers in general is that it’s possible to have a consistently lower latency compared to GCd langues: discord mentions this in their article about migrating to rust from go: https://discord.com/blog/why-discord-is-switching-from-go-to-rust
What about the user problem that Lemmy is solving requires such low latency? Discord is a real time chat service. Lemmy is not. Not saying the overall performance improvements (ie: cost to run an instance) aren’t in Rust’s favor but pointing to latency seems odd to me.
I think the devs openly stated they aren’t backend bods and asked for help optimising the database as a priority. There’s a bit of work going on on github to sort that out I think. Anyone reading this who can optimise postgresql or contribute to a database agnostic retool should probably speak to the devs as I imagine you’d be welcome.
I wish I could help so much but I doubt they’re going to retool into .net haha.
Which is fine. If they wanted to learn Rust and wrote inefficient code, good for them. I appreciate their efforts. Rust can certainly be beaten into shape and perform well enough in the end.
Rust itself or the way the Rust logic is implemented is not the bottleneck. Like most decent web applications the bottleneck is the database and how the decentralized protocols themselves are reconciled there.
Scaling massive amounts of records like Lemmy has been forced to is almost always IO bound at the database level even when a web service is centralized; this is much more difficult in federated architectures. This is why “NoSQL” databases have increased in popularity, but they are also not a magic bullet as there are major ACID trade offs one needs to consider.
NoSQL databases are no silver bullet and the costs of ACID are usually exaggerated (plus most NoSQL databases actually implement ACID anyway). NoSQL databases and SQL databases often have similar performance characteristics since most of the technology is typically the same under the hood.
Plus from my experience as a database consultant: databases are rarely IO bound, NoSQL or SQL unless you have a strange workload. Most time for query execution is usually spent waiting on loads or executing CPU instructions, not waiting on disk IO.
deleted by creator
Pulling this out of my ass, but I think the problem might be in Lemmy using websockets.
I feel like supporting 1500 simultaneous users making a request every 10-20 seconds is easier than keeping 1500 websockets alive.
Irregardless, Lemmy does feel very snappy compared to other websites I’ve had the displeasure of using. Main problem is low robustness in the RPC layer.
I maintain and host ntfy.sh, an open source push notification service. I have a constant 9-12k WebSocket and HTTP stream connections going, and I host it on a two core machine with an average load average of less than 1. So I can happily tell you that it’s not WebSockets. Hehe.
My money would be on the federation. Having to blast/copy every single comment to every single connected instance seems like a lot.
My money would be on the federation. Having to blast/copy every single comment to every single connected instance seems like a lot.
As far as I know, every server connects to every other server. Allowing for proxying messages through servers would significantly help.
I agree.
Random ideas:
The Kademlia protocol (a DHT) has a thing that associates ownership of data to the 20 closest nodes in a P2P network. If an approach like this were used, the load would be spread across those 20 nodes. I implemented that like 15 years ago or so. It was a ton of fun.
Another, simpler approach is what you suggested, simple caching of and relaying through other nodes, though that does not answer the topology of the network. How would an instance decide where to get it’s data from (a star, a tree, at random, …)? How would it be authenticated (easy to solve)? Lots of fun problems to solve. Not fun problems though if you have a pile of other problems too though…
How would an instance decide where to get it’s data from (a star, a tree, at random, …)?
I thought of it like this:
- Each instance can optionally work as a relay for other instances - this relation is called “friendship”.
- Each instance defines a friend list on their own.
- Whenever an instance is a friend of an another instance, it publishes that information for everyone to see.
- When an instance receives information from a friend, it sends it to it’s own friends.
- When an instance sends information, it:
- Creates a “send queue” that contains all the instances it wants to keep informed of it’s own activity.
- Shuffles the order of the queue.
- Iterates over instances in that queue
- Sends information to that instance
- Checks if that instance is it’s friend.
- Checks if it itself is a friend of that instance.
- If that’s true, considers that instances friends as already informed - thus removing them from the send queue.
- Else, just proceeds normally.
If an instance misbehaves by not relaying messages despite claiming to be doing so - unfriend it.
How would it be authenticated
Each instance publishes a public key that you can use to verify relayed messages.
I probably should get on to helping out developing Lemmy - it feels like there’s RFC’s to be written and interesting problems to be solved. Much more interesting than what I’m doing at work.
They’re gonna move away from we sockets within a couple of weeks, from what I hear
That’s a good move IMHO. Honestly I don’t want my UI to randomly shift down when new messages come in from syncing with another instance.
The right move would be to make a page that renders once and then only updates when you refresh the page. And then use web push for message notifications.
Wait — it uses websockets for each and every user??! That’s just completely insane and of course it will fail to scale! There is zero reason for that, have specific live threads with websockets where it makes sense (though that is only mostly a one-way communication so even there it is an overkill), but for mostly static content it is just insanely inefficient… surely I’m more than fine with that upvote appearing a minute later and not in “real time”!
As I said - I’m pulling this out of my ass. Browser debugging tools don’t support websockets well, but looking at the network log, it seems to start a websocket for every tab.
What makes you think that inefficient rust is slower than efficient Python? I mean, sure it could be possible if you are actively trying to make rust slow, but rust is multiple order of magnitude faster than python. If rust was to blame here then I don’t think any language could be fast enough.
Rust is not to blame, but that code that has been written in Rust might be to blame.
The algorithms used have more effect than the language used, and Rust might make using certain algorithms more painful and thus steer programmers towards less efficient algorithms. Using
cloneis often an example of this, it’s a little easier and gets around some borrow checker difficulties. (This is true in general, but I don’t know if this is what has happened with Lemmy.)Look at salvo [diesel] coming it at #200+ on this benchmark1, lots of programming languages have at least one framework that is faster on the microbenchmark. This isn’t especially meaningful, but it does show that, let’s say, a feature rich framework in Rust might end up being slower than a Python framework that’s laser focused on the specific use case.
There’s a catch here, something I read someone mention on Hacker News and I agree. Python is easy when you don’t care about performance; the moment you need to worry about it, all the easiness gets thrown away.
Everything is easy when you don’t care about performance.
Have you ever used py-spy? It’s an excellent profiler for Python code (written in Rust 😉). It can attach to a running process and tell you what line is taking the most time. Seems pretty easy to me. (Which is not to say Python can achieve optimal C speed.)
I don’t think there’s such an easy profiling tool for C or Rust? But I’d be happy to be proven wrong here.
Go solve 20 or 30 Project Euler problems. All of them are solvable in less than a second using Python (or any language). Write your solutions in C or Rust and you will soon see that a naive or brute-force solution in Rust will literally never finish (the heat death of the universe will come first), but a clever and efficient solution in Python takes less than a second.
This is why I say algorithms matter more than language. There’s like 2 or 3 orders of magnitude to be had by choosing the fastest language (which is to say, Rust might be 1000 times faster than Python in some cases), but there’s like 10 or 20 orders of magnitude to be saved using the right algorithms sometimes.
What makes you think that inefficient rust is slower than efficient Python?
Well of course it can be. Performance issues are very often algorithmic rather than from execution efficiency.
Rust won’t make it slow for sure, but it’s not enough to ensure it’s fast.
Its not code that seems to have difficulty scaling, it seems to be user curation and user trust that is being difficult to scale.
The lemmy.ml post that asks people to go elsewhere is still stickied and the first thing it mentions is that they have upgraded the server. So that does suggest that compute scaling is an issue.
It could also be an issue with disk i/o, data port throughput, database performance…
I mean, with all the server issues we’ve seen with the influx of users, it does seem like the code is difficult to scale
When it comes to architecture I’m not a genius, but I think a lot of how federation works is tough.
Plus, even if you have a perfectly efficient backend it can only handle so much based on the hardware you’re running on. “Struggling to scale” can just mean “struggling to afford better hardware.”
At this point I think the bottleneck is largely that every server has needed to upgrade for this wave of the reddit migration.
I think threads like this one: https://news.ycombinator.com/item?id=28440742 help explain the complexity of performance. There’s considerations from the development process, existing technology, simplicity, and more.
Whatever the performance bottlenecks are, I hope they can get them sorted so that any exponential growth caused by Reddit at the end of the month can be capitalized on.
I’ve got a feeling that other redditors who want to flee / branch out will look at these sites and so long as they see posts, comments and that it has a decent UI and loads well then people will stick around and build communities here.
I agree, hearing about scaling issues so early into adoption is concerning. Lemmy advocates say “horizontal scaling is already built in! just add more instances!”, but that doesn’t explain the problem.
It’s all just text! By my guess too, handling text alone a server should easily support a thousand concurrent users, and hundreds of thousands of daily users. A RasPI should handle thousands. I’ve heard the bottleneck is the database? In that case Rust is not to blame, Postgres is.
But my fear is that the data structures are implemented in a trivial way. If you have a good reddit-sized thread with a thousand comments, but you store each comment as a separate database entry, then every pageview will trigger a thousand database lookups! The way I imagined making a reddit clone is that I would store the comments as a flat list with some tree data on top, such that serving a single page with 1000 comments is no different that streaming a 100K text file. I’ll go take a look how Lemmy does it currently once I get the courage!
But my fear is that the data structures are implemented in a trivial way. If you have a good reddit-sized thread with a thousand comments, but you store each comment as a separate database entry, then every pageview will trigger a thousand database lookups!
I mean, I hope that surely can’t be the case. There is no reason why they wouldn’t get all of those comments in a single request even if it were separate rows in the db. I initially thought that they’d have to query each individual instance participating in a thread but even that isn’t the case because the fediverse protocol makes each instance mirror the content from others, meaning that your local instance should already have the necessary data in one place, making it easy to load it to the users.
If you have a good reddit-sized thread with a thousand comments, but you store each comment as a separate database entry, then every pageview will trigger a thousand database lookups!
No it wouldn’t, that’s called the N+1 query problem and it can be avoided by writing more efficient queries
Could you explain more how this works? I see how you should be reducing the number of SQL queries from N+1:
SELECT p.comment_ids FROM posts p WHERE p.post_id = 79 -> (5, 13, 42, 57) SELECT c.text FROM comments c WHERE c.comment_id = 5 SELECT c.text FROM comments c WHERE c.comment_id = 13 SELECT c.text FROM comments c WHERE c.comment_id = 42 SELECT c.text FROM comments c WHERE c.comment_id = 57down to 1 query:
SELECT c.text FROM comments c WHERE c.parent_post = 79(Or something like this, I don’t know SQL sorry). But wouldn’t the database still have to lookup each comment line record on the backend? Yes, they are all indexed and hashed, but if you have a thousand comments, or even ten thousand (that reddit handles perfectly fine!) - isn’t 10000 fetches from a hashtable still slower than fetching a 10000-long array? And what if you’ve been running your reddit clone for years and accumulated so many gigs of content that they don’t fit in memory and have to be stored on disk. Aren’t you looking at 10000 disk reads in worst case scenario with a hashtable?
This is when you paginate. It’s pretty cheap for the database to grab a limited amount ordered by certain criteria, you’d just need to make sure your indexes are correct.
You’ve got the right idea with your SQL example, that’s pretty much exactly what N+1 would look like in your query logs.
This can happen when using an ORM, if you’re not careful to avoid it. Many ORMs will query the database on attribute access, in a way that is not particularly obvious:
class User: id: int username: str class Post: id: int class Comment: id: int post_id: int # FK to Post.id author_id: int # FK to UserGiven this simple python-ish example, many ORMs will let you do something like this:
post = Post.objects.get(id=11) for comment in post.comments: # SELECT * FROM comment WHERE post_id=11 author = comment.author # uh oh! # SELECT * FROM user WHERE id=comment.author_idAlthough
comment.authorlooks like a simple attribute access, the ORM has to issue a DB query behind the scenes. As a dev, especially one learning a new tool, it’s not particularly obvious that this is happening, unless you’ve got some query logging that you’re likely to notice during development.A couple of fixes are possible here. Some ORMs will provide some method for fetching the comments via JOIN in the initial query. e.g.
post = Post.objects.get(id=11).select_related("comments")instead of justpost = Post.objects.get(id=11). Alternately, you could fetch the Post, then do another query to grab all the comments. In this toy example, the former would almost certainly be faster, but in a more complex example where you’re JOINing across multiple tables, you might try breaking the query up in different ways if you’re really trying to squeeze out the last drop of performance.In general, DB query planners are very good at retrieving data efficiently, given a reasonable query + the presence of appropriate indexes.
@TauZero you would use a join so that one call would fetch all comment rows for that post:
`SELECT p.post_id, p.title, p.description, c.text
FROM posts p JOIN comments c ON p.post_id = c.post_id
WHERE p.post_id = 79`
This would return a list of all comments for post 79, along with the post id, title, and description also in every row. This isn’t a perfect example of optimized SQL, and I have no idea if these are the correct table and field names, as I didn’t look them up. But it’s a simple example of joins.
“disk reads” are unavoidable. It’s finding the data in the first place that’s expensive. In an appropriately indexed database, reading a sequential range is extremely efficient. Rather than reading 10,000 times from a hash table, it’s like reading a single table into memory, which is possible because you know in advance that the data you’re looking for is there.
Bear in mind that indexing a database can include the physical organization of the data on the disk. As a simplified example, if you choose a clustered index based on, timestamp, then selecting data between 2 timestamps is as easy as locating the endpoints and reading the data sequentially off the disk. (The reality is more technically complex, but doesn’t involve much more physical work.)
Right! The trivial organization would have been to store comments by timestamp. So in my above example, how would you appropriately index the database such that comments 5, 13, 42, and 57 are stored consecutively, even though other comments to other posts arrive in between?
If you want to optimize for loading comments in a single thread in a single community in a single server in a federation, then timestamp would be a bad choice.
A simple example of an index for this use case would be something like (ServerId, ThreadId, Timestamp). By the time you want to load comments in a thread, you know the server id and thread id.
Ok, so it is possible to do! I’ve always been suspicious of databases. Loading all comments in a thread is the only thing a reddit clone has to do right. For a popular thread, it may need to be done hundreds of thousands of times (ignoring caching). Everything else, like user pages, is extra. Yet with a database, if instead of a thread I wanted to display comments made every odd Tuesday that have the structure of a haiku, I could. All that power has to be paid for somewhere!
Maybe I’m just a boomer thinking in terms of spinning rust, when everything is SSDs and 128GB+ of RAM. I wonder - do you think reddit stores its entire 18 years of content in RAM, split or duplicated between shards? But I can’t shake off the awe at the sheer throughput of contiguous read from disk. 10000 comments, 200 characters per comment = 2MB = done in 2ms. Don’t even need 200-at-a-time pagination!
Yet with a database, if instead of a thread I wanted to display comments made every odd Tuesday that have the structure of a haiku, I could.
You could, but if you want to do it very efficiently and at scale, you would probably need to specialize your data access layer:
All that power has to be paid for somewhere!
It’s paid for in the logical organization that is enforced at write-time (or during a maintenance task like rebuilding indices or recomputing statistics), where millisecond responsiveness is not as important.
do you think reddit stores its entire 18 years of content in RAM, split or duplicated between shards?
Lots of duplication across different layers to support different access patterns and reuse work between data retrieval tasks. You need to be able to efficiently access frequently requested data, ingest new data, synchronize data between the different layers, and provide a reasonable minimum efficiency for arbitrary requests.
Semi-related, here’s a story about how Discord does it.
All that power has to be paid for somewhere!


















