

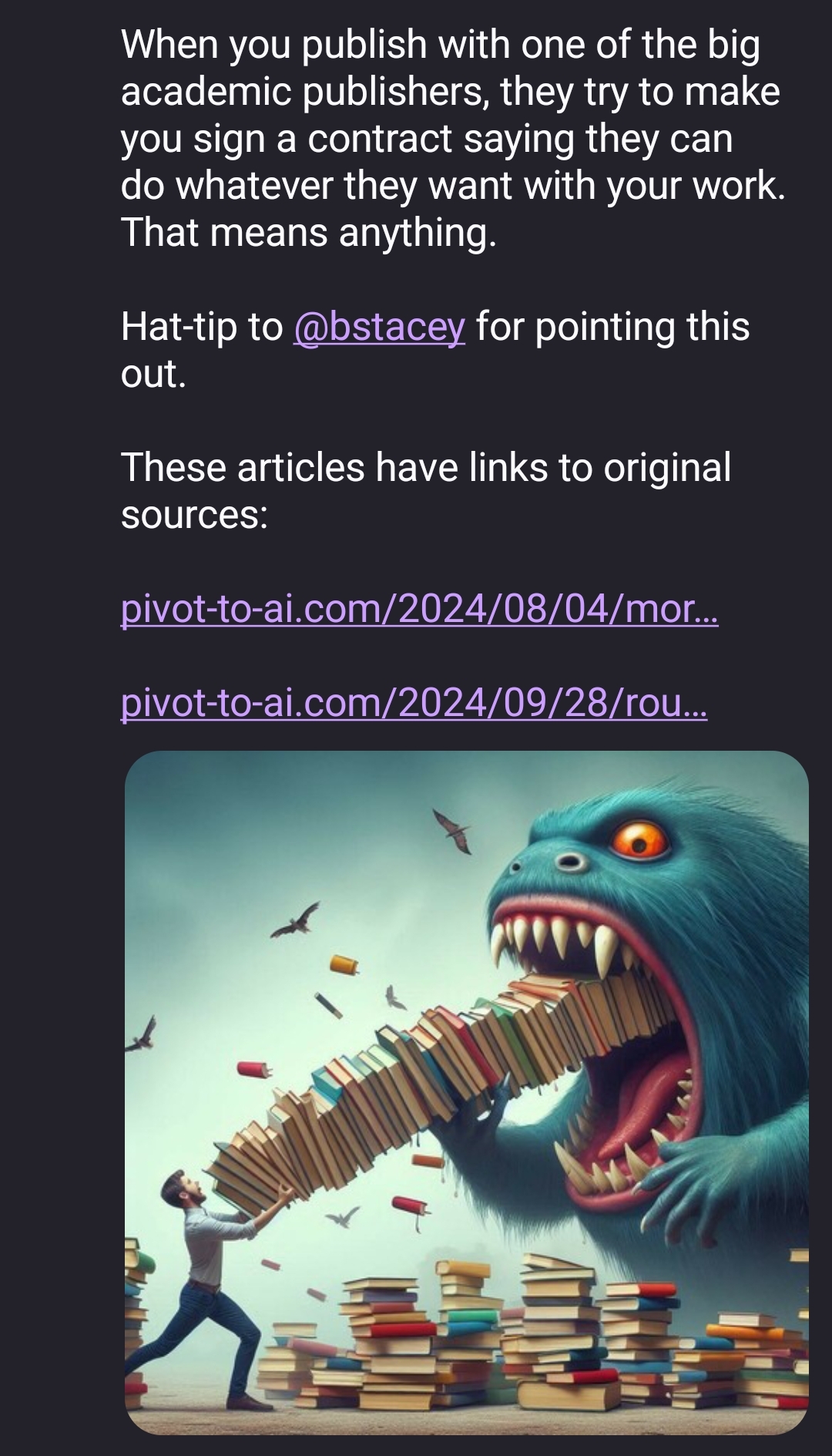
Taylor & Francis and Wiley sold out their researchers in bulk, this should be a crime.
Researchers need to be able to consent or refuse to consent and science need to be respected more than that.
You must log in or register to comment.
Daily reminder that copyright isn’t the only conceivable weapon we can wield against AI.
Anticompetitive business practices, labor law, privacy, likeness rights. There are plenty of angles to attack from.
Most importantly, we need strong unions. However we model AI regulation, we will still want some ability to grant training rights. But it can’t be a boilerplate part of an employment/contracting agreement. That’s the kind of thing unions are made to handle.
“it’s in the public interest” so all these articles will be freely available to the public. Right?.. Riiight?!
See - this is why I don’t give a shit about copyright.
It doesn’t protect creators - it just enriches rent-seeking corporate fuckwads.
Oh look! Socialism for the rich!
“How is nobody talking about this?”
The average person has the science literacy at or below a fifth grader, and places academic study precedence below that of a story about a wish granting sky fairy who made earth in his basement as a hobby with zero lighting (obviously, as light hadn’t been invented at that point).
Careful, you might cut yourself with that edge
deleted by creator
I will not be called unrealistic by a cancelled nickelodeon puppet from the 90s.
“it is in the public interest for these emerging technologies to be trained on high-quality, reliable information.”
Oh, well if you say so. Oh wait, no one has a say anyway because corporations ru(i)n everything.
It’s nice to see them lowering the bar for “high-quality” at the same time. Really makes it seem like they mean it. /s
It’s for reasons like these that I think its foolhardy to be advocating for a strengthening of copyrights when it comes to AI.
The windfall will not be shared, the data is already out of the hands of the individuals and any “pro-artist” law will only help kill the competition for companies like Google, Sony Music, Disney and Microsoft.
These companies will happily pay huge sums to lock anyone out of the scene. They are already splitting it between each other, they are anticipating a green light for regulatory capture.
Copyright is not supposed to be protecting individuals work from corporations, but the otherway around
I think this happens because the publisher owns the content and owes royalties to authors under certain conditions (which may or may not be met in this situation). The reason I think this is I had a PhD buddy who published a book (nonfiction history) and we all got a hardy chuckle at the part of the contract that said the publisher got the theme park rights. But what if there were other provisions in the contract that would allow for this situation without compensating the authors? Anywho, this is a good reminder to read the fine print on anything you sign.
I’d guess books are different, but researchers don’t get paid anything for publishing in academic journals
Oh yeah, good point.
How does cutting peer review time help get more content? The throughput will still be the same regardless of if it takes 15 days or a year to complete a peer review
Isn’t that because the peers also write stuff? So it’s not just a fixed delay on one-by-one papers, but a delay that goes between peers’ periods of working on papers too.
Meh who cares. AI is gonna be more correct now. It costs nothing to use (if you run your own locally), and nothing to not use. Just don’t use it if you hate it so much and for the love of god touch grass and get off twitter, that place is hell on earth.
Despite the downvotes I’m interested why you think this way…
The common Lemmy view is that morally, papers are meant to contribute to the sum of human knowledge as a whole, and therefore (1) shouldn’t be paywalled in a way unfair to authors and reviewers – they pay the journals, not the other way around – and (2) closed-source artificially intelligent word guessers make money off of content that isn’t their own, in ways that said content-makers have little agency or say, without contributing back to the sum of human knowledge by being open-source or transparent (Lemmy has a distaste for the cloisters of venture capital and multibillion-parameter server farms).
So it’s not about using AI or not but about the lack of self-determination and transparency, e.g. an artist getting their style copied because they paid an art gallery to display it, and the art gallery traded rights to image generation companies without the artists’ say (although it can be argued that the artists signed the ToS, though there aren’t any viable alternatives to avoiding the signing).
I’m happy to listen if you differ!
I won’t say that AI is the greatest thing since sliced bread but it is here and it’s not going back in the bottle. I’m glad to see that we’re at least trying to give it accurate information, instead of “look at all this user data we got from Reddit, let’s have searches go through this stuff first!” Then some kid asks if it’s safe to go running with scissors and the LLM says “yes! It’s perfectly fine to run with sharp objects!”
The tech kinda really sucks full stop, but it’ll be marginally better if it’s information is at least accurate.
This could be true if they were to give more weight to academic sources, but I fear it will probably treat them like any other source, so a published paper and some moron on Reddit will still get the same say on wether the Earth is round.
Hmm, that makes sense. The toothpaste can’t go back into the tube, so they’re going a bit deeper to get a bit higher.
That does shift my opinion a bit – something bad is at least being made better – although the “let’s use more content-that-wants-to-be-open in our closed-content” is still a consternation.
Not wrong there, it’s one of the things that makes me critical of genai




{kind=link}